

Điện toán đám mây (Cloud Computing) được xem như là 1 giải pháp toàn diện cho các chủ doanh nghiệp trong việc xây dựng cơ sở hạ tầng về CNTT thông qua Internet. Hiện nay lĩnh vực này đang là cuộc cạnh tranh khốc liệt giữa các ông lớn như Google, Amazon hay Microsoft. Trong nỗ lực cải thiện chất lượng lưu trữ dữ liệu của mình, mới đây Google đã giới thiệu công cụ Big Lake cùng với những cam kết hỗ trợ tất cả các định dạng dữ liệu phi cấu trúc trên nền tảng Google Cloud.
Vậy nên, việc liên tục update những cải tiến mới về Google Cloud sẽ là một lợi thế cho các Devops Engineer. Ở bài viết này chúng ta cùng đi tìm hiểu về những nội dung cập nhật trên để xem Google đã có bước tiến thế nào trong lĩnh vực điện toán đám mây này nhé.
GCP, GCB, Big Lake là gì?
Google Cloud Platform (GCP) là một nền tảng điện toán đám mây (Cloud Computing) do Google cung cấp, bao gồm gần 100 dịch vụ được lưu trữ để tính toán, lưu trữ và phát triển ứng dụng chạy trên phần cứng của Google.
GCP cho phép các doanh nghiệp, tổ chức xây dựng và chạy các ứng dụng của mình trên chính hệ thống mà Google cung cấp, đồng thời được sử dụng tất cả các dịch vụ thiết yếu của Google bao gồm Big Data, Storage, Compute Engine, Networking, Developer Tool, …

Cùng với Azure của Microsoft và AWS của Amazon, GCP là 1 trong 3 nền tảng điện toán đám mây hàng đầu hiện nay cho việc phân phối các tài nguyên CNTT theo nhu cầu thông qua Internet.
Google Cloud Big Query (GCB) là 1 công cụ nội bộ của Google dùng để truy vấn một khối lượng dữ liệu khổng lồ trên nền tảng hạ tầng của chính Google. GCB được xem như 1 data warehouse có khả năng mở rộng cao, Google thiết kế chúng để giúp các nhà phân tích dữ liệu làm việc nhanh và hiệu quả hơn với 1 chi phí hợp lý, thay vì việc phải tự xây dựng 1 cơ sở hạ tầng có sẵn cho riêng từng doanh nghiệp.
Trong hội nghị dữ liệu đám mây diễn ra vào tháng 4/2022 vừa qua, Google đã công bố bản phát hành của Big Lake, 1 công cụ lưu trữ hợp nhất mới giúp hỗ trợ các doanh nghiệp trong việc phân tích dữ liệu trong kho data warehouse và data lake của họ 1 cách dễ dàng hơn. Khái niệm Data Lake dùng để chỉ hình thức lưu trữ dữ liệu bao gồm cả loại dữ liệu phi cấu trúc và có cấu trúc từ nhiều nguồn khác nhau; phân biệt với hình thức Data Warehouse trong bài toán lưu trữ dữ liệu lớn (Big Data).
Ý tưởng cốt lõi của Google là việc tận dụng khả năng hoạt động và quản lý dữ liệu kho (warehouse) Big Query mở rộng sang data lakes trên Google Cloud Storage để có thể kết hợp thành 1 dịch vụ duy nhất.
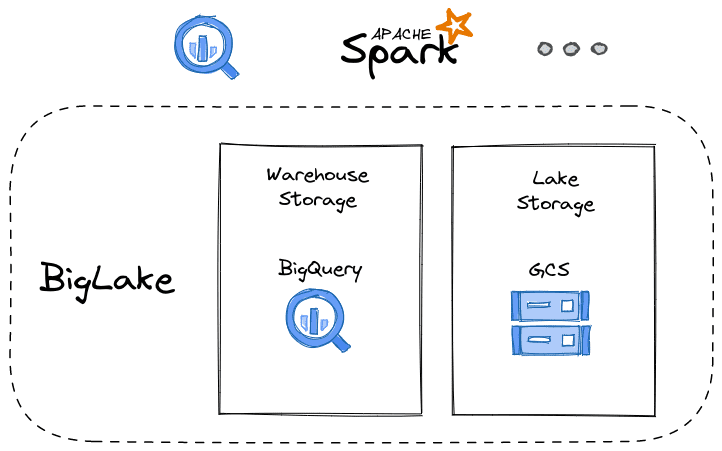
BigLake hỗ trợ chính thức Apache Iceberg
BigLake lúc ra mắt đã hỗ trợ người dùng lưu trữ dữ liệu ở các định dạng file mở, chẳng hạn như Apache Parquet – 1 định dạng dữ liệu theo cột.
Trong nỗ lực tiếp tục hỗ trợ các loại dữ liệu phi cấu trúc của mình, cuối tháng 10 vừa rồi trong 1 thông báo tại hội nghị Google Cloud Next, Google chính thức thông báo hỗ trợ định dạng Apache Iceberg – 1 định dạng hiệu suất cao mã nguồn mở cho các bảng phân tích khổng lồ. Ice berg là 1 định dạng mã nguồn mở phổ biến cho khách hàng đang tìm cách xây dựng các Data Lakes, nó cung cấp nhiều tính năng sẵn có trong kho dữ liệu (data warehouse).
Link bài thông báo của Google Cloud:
https://cloud.google.com/blog/products/data-analytics/announcing-apache-iceberg-support-for-biglake
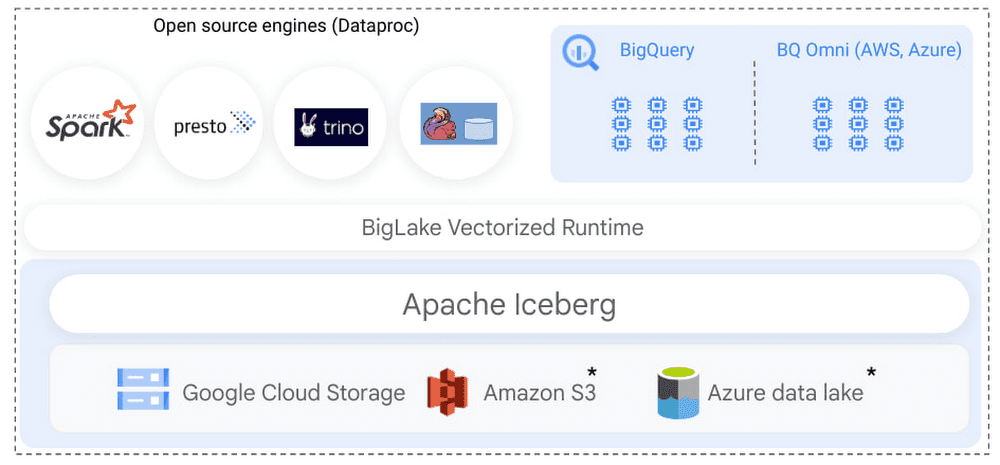
Đặc điểm kỹ thuật mở của Iceberg cho phép khách hàng chạy nhiều công cụ truy vấn trên 1 bản sao dữ liệu duy nhất được lưu trữ. Với sự hỗ trợ từ cộng đồng thì định dạng Apache Iceberg đang trở thành 1 tiêu chuẩn cho data lakes, mang lại khả năng tương tác trên các cloud cho công việc phân tích dữ liệu kết hợp với các hệ thống trao đổi dữ liệu.
Tiếp theo sẽ là Hudi và Delta Lake
Cũng trong thông báo trên của mình, Google Cloud cũng đã hứa hẹn việc sẽ hỗ trợ thêm các định dạng dữ liệu Hudi và Delta Lake trên công cụ Big Lake trong tương lai, mặc dù chưa có kế hoạch chính thức cho thời điểm hỗ trợ. Apache Hudi là 1 framework quản lý dữ liệu mã nguồn mở được sử dụng để đơn giản hóa quá trình xử lý dữ liệu gia tăng và phát triển dữ liệu pipeline. Delta Lake là 1 lớp định dạng lưu trữ mã nguồn mở mang lại độ tin cậy, bảo mật và hiệu suất tốt hơn trên data lake, bao gồm cả các xử lý streaming. Theo như số liệu của viện nghiên cứu Ventana, có hơn 57% những người sử dụng data lakes đang sử dụng ít nhất một trong những định dạng dữ liệu bảng Iceberg, Hudi hay Delta. Việc BigLake GCP hỗ trợ được cả 3 định dạng dữ liệu trên hứa hẹn mang đến nhiều tiện ích cho người sử dụng trong việc xử lý dữ liệu. Các đối thủ của Google Cloud cũng đã hoặc đang có kế hoạch về việc công bố hỗ trợ các định dạng trên trong hội nghị thường niên CloudWorld sắp tới.
Big Query hỗ trợ dữ liệu phi cấu trúc
Một điểm cập nhật đáng chú ý nữa từ Cloud Next, Google cũng đã thêm các tính năng mới vào kho dữ liệu doanh nghiệp được quản lý của mình – Big Query – bao gồm việc bổ sung hỗ trợ cho dữ liệu phi cấu trúc. Theo Google, chỉ 10% dữ liệu mà các doanh nghiệp sử dụng và tạo ra là nhóm dữ liệu có cấu trúc – đấy là các dữ liệu hoạt động, các ứng dụng SaaS hay dữ liệu bán cấu trúc lưu dưới dạng JSON. Dữ liệu phi cấu trúc chiếm đa số gồm các video, âm thanh và các tài liệu ở định dạng khác nhau, do đó các doanh nghiệp phải đối mặt với việc nhu cầu làm việc với dữ liệu phi cấu trúc ngày càng tăng. Động thái này của Google được xem như 1 sự khác biệt với các nền tảng Cloud khác, nó giúp tạo ra 1 nền tảng duy nhất hứa hẹn đơn giản hóa mọi thứ cho các nhà khoa học dữ liệu và phát triển khi sử dụng.
Kết bài
Trong lĩnh vực điện toán đám mây Cloud Computing hiện nay, thị phần của Google Cloud vẫn đang xếp sau khá nhiều so với Azure của Microsoft và đặc biệt là AWS của Amazon.
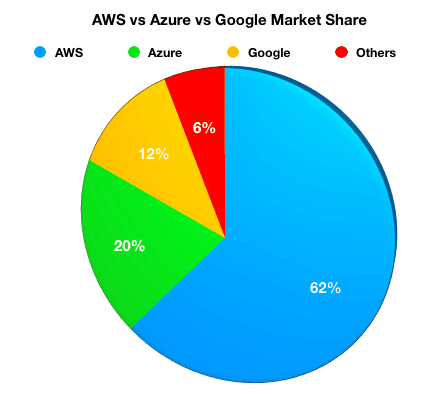
Với những động thái tích cực, cải tiến việc hỗ trợ nhiều định dạng dữ liệu phi cấu trúc trên, hy vọng sẽ là bước phát triển tốt của Google Cloud nhằm chiếm lấy thị phần trong thị trường Cloud hiện nay. Điều quan trọng là người sử dụng ngày càng có nhiều công cụ và tiện ích hơn trong việc phát triển hạ tầng và phân tích dữ liệu trên các nền tảng đám mây. Hy vọng bài viết này đã mang lại cho các bạn những thông tin hữu ích, hẹn gặp lại các bạn trong các bài viết sau của mình.
Anh em có thể tham khảo tin tuyển dụng IT để phát triển sự nghiệp nhé!
Tác giả: Phạm Minh Khoa
Xem thêm:
Java Developer là gì? Lộ trình để trở thành Java Developer
AngularJS Là Gì? Khác Biệt Nào Giữa Angular Và Frontend Framework Khác








 là gì? Đặc điểm và ứng dụng của Big Data")


