

Bài viết đến từ anh Vũ Tuấn Nghĩa – Quản lý cao cấp hoạch định dữ liệu Data Engineering team @Techcombank
Data orchestration là một khối xây dựng cốt lõi của các hệ thống ETL dữ liệu, và là một công cụ đã có từ lâu đời và được áp dụng trong nhiều hệ thống khác nhau. Khi xây dựng Data Lake tại Techcombank, chúng mình có cơ hội thiết kế nhiều component/system từ đầu, từ hệ thống Data sourcing đến Datalake, đến hệ thống data ETL pipeline trên các zones của Data Lake. Để đáp ứng các nhu cầu và thách thức thực tế, ta cần có một hệ thống Data orchestration để giải quyết các bài toán:
- Cơ chế trigger các downstream job một cách linh hoạt mà không gây khó khăn trong quá trình vận hành
- Rút ngắn thời gian phát triển, xây dựng và kiểm thử
- Hạn chế sự phụ thuộc lẫn nhau gây ra chain failure
Hôm nay chúng ta sẽ tìm hiểu về Data orchestration và cách giải quyết bài toán ở Techcombank.


Data Orchestration là gì?
Data orchestration là nền tảng platform có nhiệm vụ quản lý và tự động hoá flow của data xuyên suốt giữa các hệ thống, application và các hệ thống lưu trữ.
Có thể hiểu đơn giản như như hình dưới như sau:
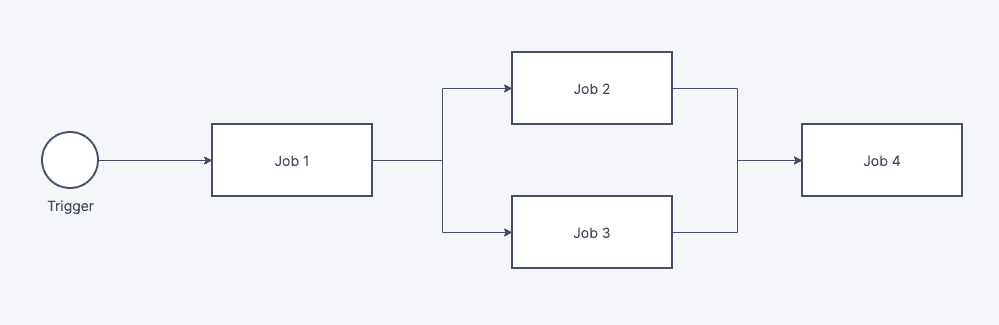
- Khi có 1 lệnh trigger
- Job 1 được execute
- Khi Job 1 done, Job 2 và Job 3 được execute
- Khi Job 2 và Job 3 cùng done, Job 4 được execute
Nhu cầu cần một Data Orchestration xuất hiện khi có dependency giữa các hệ thống. Khi có một job phụ thuộc vào job khác, thì sẽ cần 1 hệ thống ở giữa để không chỉ trigger mà còn đảm bảo với từng Job riêng biệt, chỉ được bắt đầu sau khi tất cả các phần phụ thuộc đã hoàn tất (ví dụ: Job 4).
Sự phát triển của Data Orchestration patterns
First Gen – Flight schedule
Phiên bản đầu tiên cũng như cổ điển nhất của Orchestration, được dùng khá phổ biến ở nhiều IT system (ví dụ: hệ thống giờ bay của máy bay).
Job được trigger dựa theo fixed time hoặc interval time và không phụ thuộc vào các job upstream có hoàn tất hay không. Để phòng trừ trường hợp các Job chạy tốn thời gian hơn kế hoạch, thường sẽ thêm các buffer giữa các job.

Điểm hạn chế của design này là cũng chính là task delay – buffer time
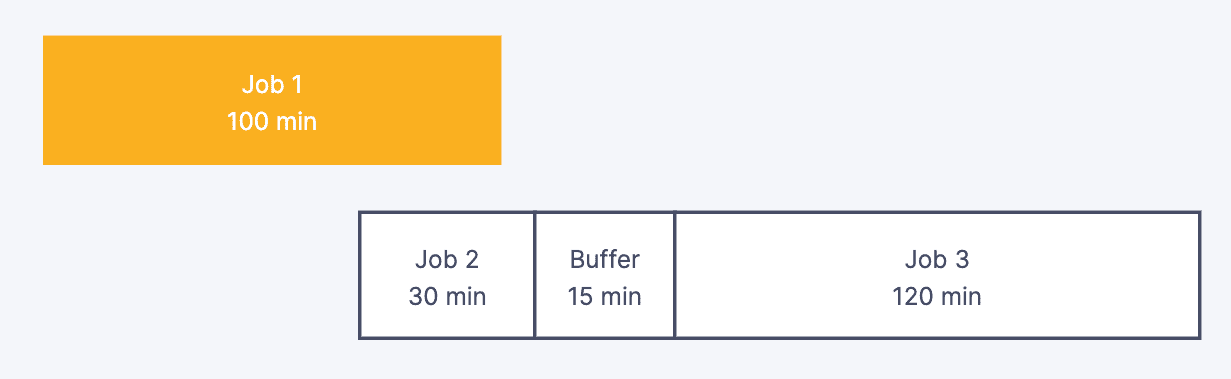
Lúc này Job 2 sẽ nhận stale input data khiến data output của Job 2 cũng sai, dẫn đến cả pipeline đang xử lý data bị sai lệch.
Current Gen – Train schedule

Phiên bản orchestration được sử dụng rộng rãi trong các software hiện đại ngày nay, nổi bật có Airflow, Dagster, Prefect, và dbt. Core concept sử dụng Directed Acyclic Graph (DAG) để định nghĩa sự phụ thuộc giữa các job và stateful application để quản lý trigger và start job.
Điểm hạn chế của design này là
- Mono-DAG
Việc sử dụng DAG để liên kết phụ thuộc giữa các job với nhau, dẫn đến trong quá trình phát triển
a. việc liên tục thêm những job vào dẫn đến “mạng nhện” DAG, khiến chi phí maintain bao gồm: compile, test càng ngày càng tăng cao khiến development cycle chậm dần theo thời gian.
b.
c. việc xác định owner of DAG cũng là vấn đề nhức đầu, nhất là khi có issue, việc ảnh hưởng đến nhiều job (nhiều team) khiến chi phí phối hợp rất tốn nhiều thời gian.
2. DAG of DAG
Một hướng giải quyết khác là thay vì sử dụng một mono-DAG, chúng ta sẽ tạo DAG of DAG. Tuy nhiên ta lại gặp phải vấn đề lớn là do giờ đây tầng phụ thuộc là DAG, sẽ giảm sự linh hoạt trong định nghĩa sự phụ thuộc của các job, nhất là trong trường hợp các data flow quan trọng, với SLA thấp.
Bài toán ở Techcombank
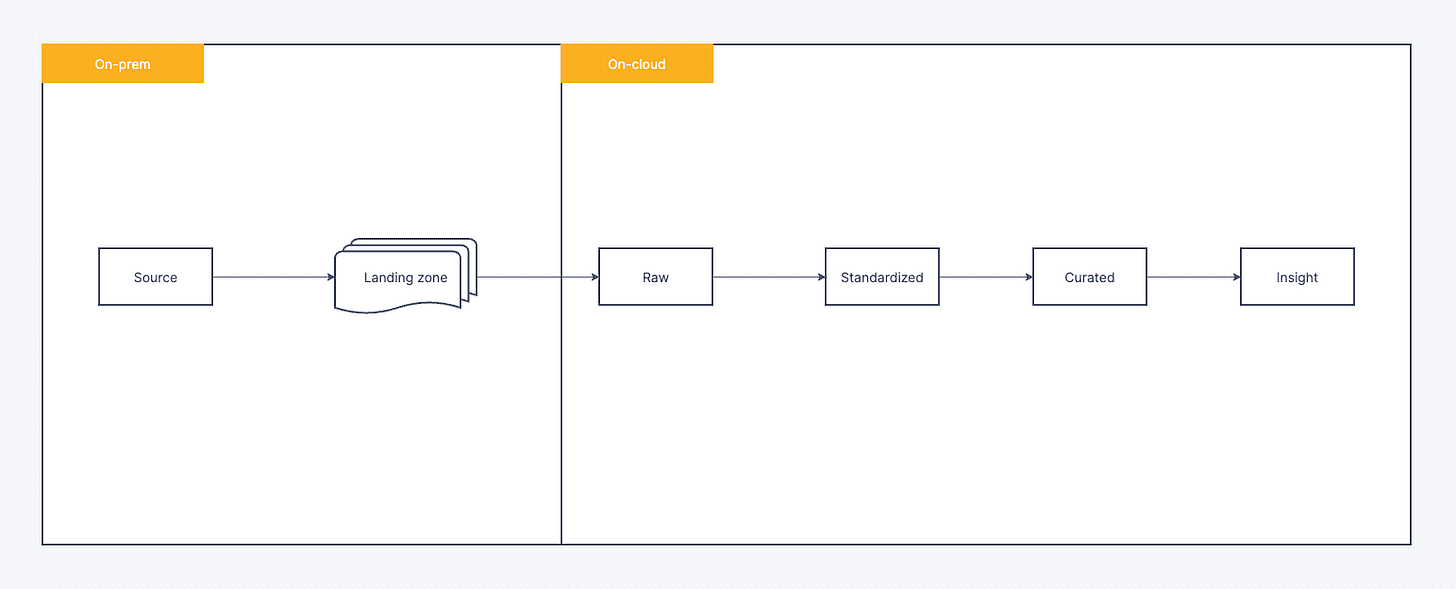
Hệ thống Datalake của Techcombank được chia làm 2 part:
- ETL Sourcing dữ liệu từ tất cả các hệ thống Data sources, tập kết data ở Raw zone, do đặc thù đơn giản về mặt nghiệp vụ, không có transformation, không dependency → Data orchestration sử dụng Airflow – out of the box solution.
- Với các ETL giữa các zone trên On-cloud Datalake, các ETL về mặt nghiệp vụ yêu cầu các dependency phức tạp, việc sử dụng các stateful Orchestration(current Gen) như Airflow hay AWS StepFunction gặp phải nhiều khó khăn trong quá tình development or operation (mono-DAG và DAG of DAG) → dẫn đến không đáp ứng được nhu cầu sử dụng của các team development.
Từ đó team mình có phát triển framework Orchestration để giải quyết bài toán gặp phải.
Event-driven Orchestration
Thay vì build 1 hệ thống centralized stateful orchestration thì team mình tiếp cận theo một mindset khác:
- Condition-based over state
- Events within queue over hardly dependency
- Configuration as code over code-first approach
Condition-based over state
Việc sử dụng Conditions để xác định xem khi nào job được trigger thay vì đơn giản dùng state của upstream job khiến việc config trigger rất linh hoạt trong quá trình sử dụng. Sau đây là một số ví dụ trong quá trình sử dụng:
Condition để trigger job khi cả 2 job_1, job_2 succeeded
{ "trigger_events":[ "job_1", "job_2" ], "conditions": [ { "name": "all_jobs_succeeded", "params": { "job_ids": [ "job_1", "job_2" ], "within": 86400 } } ] }
Condition để trigger job khi đến ngày 5 or 18 của tháng và lần chạy của job cuối cùng success
{ "trigger_events": [ { "schedule_expression": "cron(45 01 * * ? *)" } ], "conditions": [ { "name": "is_date_of_month", "params": { "days": [ 5, 18 ] } }, { "name": "last_run_succeeded" } ] }
Những functions như “last_run_succeeded“, “all_jobs_succeeded” đều là những custom function, do đó khi có nhu cầu trigger theo một logic nào đó, các bạn engineer hoàn toàn có thể contribute vào core Orchestration framework.
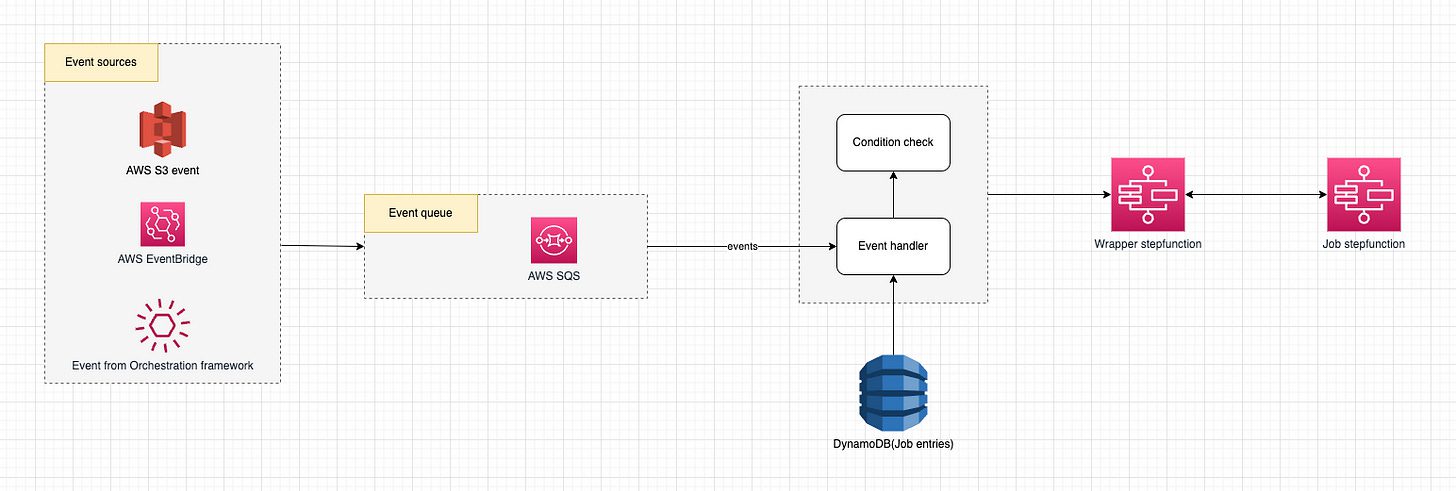
Events within queue over hardly dependency
Thay vì dùng DAG để định nghĩa dependency giữa các Job một cách chặt chẽ, chúng ta sẽ dùng queue system(ở đây bọn mình dùng AWS SQS) để decoupling giữa producer và consumer từ đó giải quyết:
- Không còn Mono-DAG – mỗi Job được định nghĩa độc lập ở small unit DAG, mỗi khi job hoàn thành, sẽ bắn ra event với naming đã được định nghĩa trong config
{"finish_events": [ { "name": "job_1_completed" } ] } - Tăng tốc độ build và testing time – do mỗi DAG được định nghĩa độc lập và ở small unit nhất do đó tăng thời gian development và testing
Configuration as code over code-first approach
Hệ thống Datalake theo đuổi mindset “Configuration as Code“
để tách biệt Operation khỏi development từ đó tăng tốc khả năng release của các system, hầu hết các system của Datalake ở Techcombank đều có 2 repo:
- Repository chứa core code logic
- Repository chứa configuration
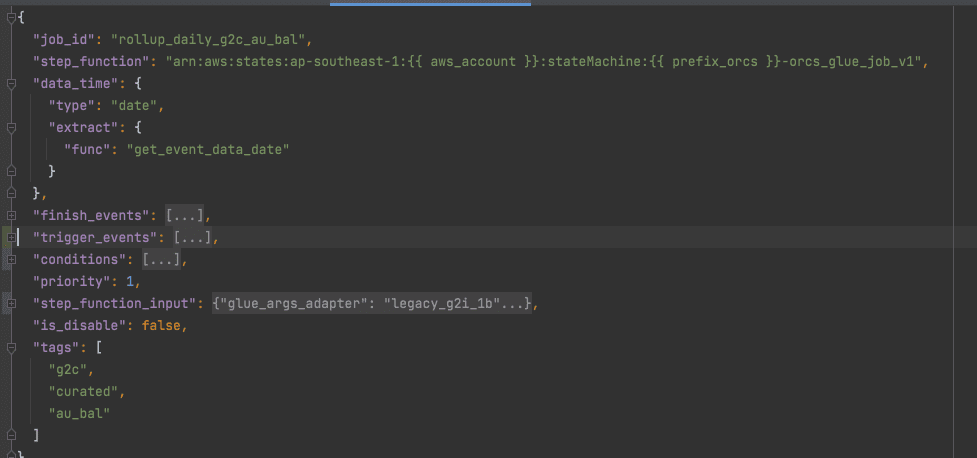
Sau đây là ví dụ một ví dụ 1 config:
Kết luận
Dù đã đáp ứng được hầu hết các nhu cầu sử dụng đồng thời khá hiệu quả trong quá trình development và operation, nhưng Data orchestration framework ở Techcombank vẫn còn nhiều điểm đang phát triển thêm:
- Resource manager
- Retry mechanism: back-off retry and dead letter queue

Các cơ hội việc làm tại Techcombank

Bài viết liên quan

Data Lake - Nền tảng lý trí cho mọi quyết định tài chính

Data Modeling with DynamoDB: Single table design (Xây dựng mô hình dữ liệu với DynamoDB: Thiết kế bảng đơn lẻ)

