

Trong vòng 6 tháng vừa qua, tôi đang phát triển một ngôn ngữ lập trình gọi là Pinecone. Sẽ còn là quá sớm để kết luận rằng nó đã hoàn hảo, nhưng Pinecone đã có nhiều tính năng hoạt động hiệu quả cho việc lập trình, bao gồm:
- Variables
- Functions
- User defined structures
Trước hết, tôi sẽ nói với các bạn rằng tôi không phải là một chuyên gia lập trình, lại càng không biết mình đang làm cái quái gì, tới giờ cũng vậy. Tôi cũng chả qua được một lớp học bài bản nào, chỉ có học chút đỉnh từ internet rồi cứ lao vào “vọc”, nhiều khi còn bỏ qua nhiều lời khuyên, hướng dẫn.
Ấy thế, mà tôi vẫn tạo ra được một ngôn ngữ lập trình mới. Đã vậy lại hoạt động tốt thế mới hay chứ. Điều đó có nghĩa tôi đã làm điều gì đó đúng.

Trong bài viết này, tôi sẽ cho các bạn thấy điều cốt lõi ở Pinecone (cũng như các ngôn ngữ lập trình khác) để có thể biến các dòng code thành ma thuật thần thánh.
Ngoài ra, tôi cũng sẽ nói về những kinh nghiệm đánh đổi bằng xương máu của mình để đi đến những quyết định then chốt tạo ra Pinecone như bây giờ.
Đây không phải là một bài hướng dẫn chi tiết về cách viết một ngôn ngữ lập trình nhưng nó sẽ là mốc bắt đầu cho những bạn muốn biết về ngôn ngữ lập trình.
Điểm khởi đầu
“Nói thật là em chả biết phải bắt đầu từ đâu cả !” – đó là câu nói mà tôi vẫn thường nghe từ các lập trình viên khác khi nói về việc viết một ngôn ngữ lập trình mới. Nếu đó cũng là phản ứng của bạn thì đừng lo, tôi đã chuẩn bị một list các quyết định cần đưa ra và những bước cần phải thực hiện khi bắt đầu viết một ngôn ngữ lập trình mới.
Compiled vs Interpreted
Có 2 loại ngôn ngữ chính: Biên dịch (Compiled) và thông dịch (Interpreted)
- Ngôn ngữ biên dịch là ngôn ngữ lập trình mà những trình biên dịch có thể biên dịch mã nguồn thành ngôn ngữ máy. Sau đó được lưu lại để executed sau (Compiled).
- Với một số ngôn ngữ, mã nguồn có thể được thực thi từng dòng một bởi một chương trình được gọi là trình thông dịch (Interpreted).
Theo lí thuyết thì bất cứ ngôn ngữ lập trình nào cũng sử dụng compiled và interpreted được nhưng tùy vào hiệu quả mà sẽ tập trung vào chỉ dùng compiled hoặc interpreted thôi. Thường thì interpreted sẽ linh hoạt hơn trong khi compiled sẽ cho hiệu năng cao hơn. Nhưng đây chỉ là bề nổi của một tảng băng vốn phức tạp hơn nhiều.
Bản thân tôi đề cao tính hiệu quả và năng suất vì thế mà tôi nhận ra có rất ít các ngôn ngữ lập trình vừa có hiệu năng cao trong khi vẫn dễ hiểu để người dùng tiếp xúc, chính vì thế mà tôi chọn compiled cho Pinecone.
Đây là một quyết định quan trọng cần phải có ngay từ đầu bởi việc viết ngôn ngữ lập trình sẽ bị ảnh hưởng rất nhiều.
Tuy nói rằng Pinecone được viết theo hướng compiled, nó vẫn có full chức năng của interpreter. Tôi sẽ giải thích cho các bạn lí do ở phần sau của bài viết.
Chọn ngôn ngữ lập trình
Các bạn hẳn cũng đã rõ, tự ngôn ngữ lập trình đã là một chương trình rùi thế nên mà bạn phải biết đọc và viết nó. Tôi thì chọn C++ tại nó có hiệu năng cao mà lại bao gồm nhiều tính năng khá hữu ích. Một phần khác là vì tôi cũng khoái C++
Còn nếu bạn muốn viết một ngôn ngữ lập trình dạng thông dịch (interpreted) thì nó càng phải viết theo hướng compiled ( sử dụng C,C++ or Swift) bởi hiệu năng bị mất trong quá trình thông dịch ngôn ngữ sẽ được khắc phục nhờ vào compiled. Ngược lại với compile thì bạn dùng một ngôn ngữ lập trình “chậm hơn” (Python hoặc là JavaScript) để dù tốc độ compile có giảm đi nhưng vẫn còn hơn là ứng dụng chạy bị lỗi hoặc không ổn định.
Level Design phải cao
Có thế hiểu một ngôn ngữ lập trình có cấu trúc như một cái ổng dẫn nước vậy. Nó sẽ có nhiều tầng khác nhau, và mỗi tầng sẽ là những data được định dạng theo một cách riêng biệt. Ngoài ra nó còn có chức năng chuyển đổi data từ tầng này sang tầng khác.
Tầng đầu tiên sẽ là một string chứa tất cả input source file còn tầng cuối cùng sẽ là kết quả khi app chạy thành công. Các bạn sẽ hiểu rõ hơn về cấu trúc “ống nước” của Pinecone sau khi đọc hết bài viết này.
Lexing
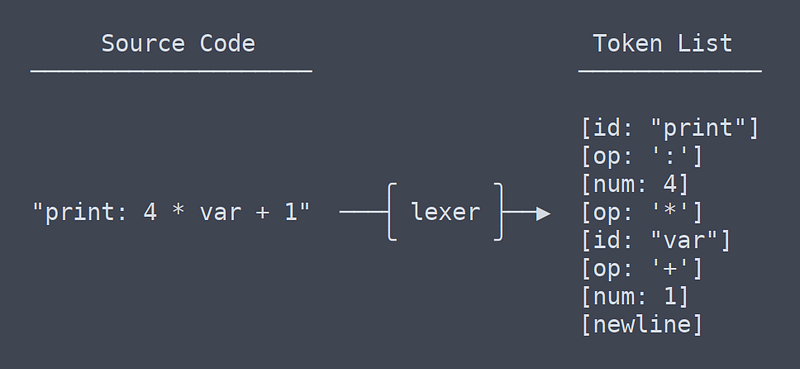
Bước đầu tiên của hầu hết các ngôn ngữ lập trình là Lexing. “Lex” là chữ cái viết tắt ám chỉ việc phân tích từ vựng. Nói cách khác, Lexing tức là chia cắt các đoạn text thành các token riêng biệt.
Tokens
Có thể hiểu Token là một đơn vị nhỏ của ngôn ngữ. Một Token có thể là một variable, tên của function, operator hoặc đơn giản là số.
Nhiệm vụ của Lexer
Lexer sẽ chia string chứa toàn bộ file của mã nguồn thành một list nhiều string nhỏ chứa các token khác nhau.
Bởi các tầng cao hơn trong cấu trúc “ống nước” của Pipecone sẽ không quay về lấy thông tin từ mã nguồn nữa mà Lexer sẽ đảm nhiệm cung cấp tất cả các thông tin cần cho các stage đó. Nguyên nhân cho việc này là bởi vì để Lexer có thể làm những nhiệm vụ như xóa comments, xác định được token nào là số hoặc là identifier. Như vậy sẽ giúp bạn không phải lo lắng về những qui định khi viết một ngôn ngữ lập trình.
Flex
Ngày đầu tiên tôi bắt đầu viết ngôn ngữ lập trình, việc trước hết tôi làm là tạo ra một Lexer đơn giản. Sau một thời gian, tôi lại tiếp tục học được nhiều tool giúp cho Lexer chở nên đơn giản hơn, ít bị bug hơn.
Flex là một trong những tool đó. Vốn là một phần mềm tạo ra Lexer. Bạn đưa vào một file chứa cú pháp đặc biệt để miêu tả ngữ pháp của ngôn ngữ mà bạn muốn viết. Flex sẽ tạo ra một phần mềm sử dụng C với tính năng lexing một string và cho ra kết như bạn muốn.
Quyết định của tôi
Dù Flex khá là hữu ích nhưng tôi quyết định vẫn sử dụng Lexer do chính tôi làm ra bởi dù sao thì nó chỉ có vài trăm dòng code, chạy khá êm mà cũng rất tiện cho tôi để chỉnh sửa cũng như thêm operator cho ngôn ngữ mà không cần phải sửa nhiều file khác nhau.
Trình phân tích cú pháp – Parsing

Nhiệm vụ của Parser
Parser thêm cấu trúc cho list của tokens sau khi được tạo ra bởi lexer. Để ngăn sự mơ hồ, bộ phân tích cú pháp (Parser) phải đưa vào ngoặc đơn và thứ tự hoạt động. Thật sự parser không hề khó nhưng khi ngôn ngữ được phát triển thì Perser sẽ trở nên phức tạp hơn.
Bison
Lần nữa, ta lại phải đưa ra quyết định liên quan đến library của một nhóm thứ 3 bên ngoài. Một trong những thư viện parsing mạnh nhất là Bison bởi nó hoạt động khá giống Flex. Bạn viết 1 file với format bất kì để chứa thông tin về ngữ pháp của ngôn ngữ đó, sau đó Bison sẽ dựa vào đó để tạo ra 1 phần mềm C để thực hiện Parsing cho bạn. Nhưng tôi thì lại không xài Bison.
Tự làm vẫn tốt hơn
Với Lexer, lựa chọn tự dùng code của mình đối với tôi là điều hiển nhiên. Bởi lexer thật chất chỉ là một phần mềm không đáng kể đến mức nó khiến tôi cảm thấy hơi bị ngốc luôn nếu mà không tự làm được. Thế nhưng với Parser thì đó lại là chuyện hoàn toàn khác. Chương trình Parser của Pinecone hiện tại dài tới 750 dòng code, đó là chỉ sau 3 lần tôi phải viết lại bởi nó chạy dở như hạch.
Điều khiến tôi đưa ra quyết định này là bởi một vài lí do như sau:
- Giảm thiểu chuyển đổi ngữ cảnh/thông tin: khối lượng thông tin phải chuyển đổi qua lại giữa C++ và Pinecone đã đủ tệ rùi, giờ mà còn cho Bison vào nữa thì chắc nó “banh xác” luôn.
- Để build nó đơn giản: Cứ mỗi lần thay đổi ngữ pháp thì Bision lại phải chạy trước cái buid. Dù là có thể để auto tự chạy những việc cứ phải đổi qua lại các build system thì cũng đủ chán nản rùi.
- Tôi thích build cái gì nó ngầu vãi ra: Ngay từ đầu khi bắt đầu viết Pinecone tôi vốn đã không cho rằng nó dễ. Nếu đã thế thì chơi khó luôn, sao phải sợ mà đưa vị trí trung tâm quan trọng cho những đứa khác chứ (ý là để các phần mềm làm giúp).
Ngay từ đầu tôi đã biết rõ con đường mình chọn vốn không hề đơn giản thế nhưng tôi vẫn tự tin nhờ vào những gì mà Walter Bright nói:
“Biết là thế nào cũng gây tranh cãi khi nói điều này, nhưng tôi sẽ không lãng phí thời gian với Lexer hay Parsen đâu. Chúng rất tốn thời gian. Viết một lexer và parser chỉ chiếm một tỷ lệ rất nhỏ trong công việc viết một trình biên dịch (compiler). Cả cái thời gian mà bạn xài mấy cái trình đó thì tự mình viết còn nhanh hơn. Đã thể sử dụng mấy cái trình tạo ra lexer hay parser còn thường xuyên báo lỗi, ồn ào đến mệt người”
Action Tree
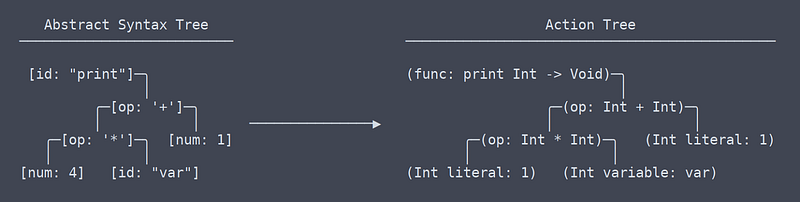
Action tree theo như tôi hiểu thì nó liên quan tới LLVM’s IR (intermediate representation). Mặc dù có vẻ giống nhau như thật ra bản chất của action tree rất khác biệt so với syntax tree. Tôi đã phải mất một khoảng thời gian để tìm ra được điểm khác nhau giữa chúng.
Action Tree vs AST
Nói nôm na thì Action tree chính là AST nhưng thêm context (thông tin) vào. Những context đó là thông tin về loại function nào hoặc là vị trí mà 1 variable được sử dụng. Bởi vì Action tree cần phải biết và nhớ được những thông tin đó nên phần mềm tạo ra Action tree cũng cần rất nhiều namespace và những thứ khác.
Chạy Action Tree
Khi ta đã có một action tree thì việc chạy code sẽ trở nên dễ dàng. Mỗi action node đều có một function “execute”, chúng sẽ lấy các thông tin input để thực hiện những mệnh lệnh được đưa ra để có thể cho ra output là kết quả những mệnh lệnh đó. Đó cũng là cách interpreter hoạt động.
Lựa chọn để Compiling
“Ủa chẳng phải Pinecone vốn đã compiled rồi mà?”. Bạn đúng rồi đấy! nhưng compiling nó có nhiều cách lắm.
Tự tạo Compiler
Bạn đầu khi mới viết Pinecone thì nghe có vẻ là ý tưởng hay. Bạn cũng biết rùi đấy, tôi thích tự làm, tự “vọc” và tự chế. Thế nhưng việc viết một chương trình compiler nhỏ gọn lại cực kì khó. Đồng thời bởi vì số lượng các thiết kế, cấu trúc và hệ điều hành mà gần như là bất khả thi cho việc tạo ra một compiler backend với đa nền tảng mà chỉ có một cá nhân. Ngay đến cả team của các ngôn ngữ lập trình nổi tiếng như Swift, Rust hay Clang còn chán nản và phải dùng đến những chương trình sau:
LLVM
LLVM là một chương trình tổng hợp của các compiler tools. Nói cách khác, LLVM là một libary giúp biến ngôn ngữ lập trình của bạn thành một thư viện biên soạn chất lượng. Nghe thì có vẻ khá là hoàn hảo đúng không? Thật tiếc là nếu bạn không có chuẩn bị thì dễ “chết đuối” y như tôi. LLVM là một library cực kì đồ sộ và phức tạp. Tôi nhận ra mình phải bỏ ra một khoảng kha khá thời gian để có thể sử dụng LLVM được cho Pinecone.
Transpiling
Vừa muốn Pinecone được viết theo hướng compiled lại muốn hiệu năng phải cao, tôi quyết định sử dụng 1 phương thức khác là transpiling (chuyển đổi)
Tôi viết một chương trình Pinecone cho C++ transpiler, rồi lại thêm tính năng tự động compile cũng như cho ra output với GCC. Hiện tại thì cách này hiệu quả với phần lớn các chương trình của Pinecone. Dù không nhỏ gọn cũng chẳng có được sự tinh tế nhưng ít ra thì nó hoạt động khá suôn sẻ.
Tương lai
Nếu mà vẫn có thể tiếp tục phát triển Pinecone thì chắc chắn là nó sẽ phải có LLVM compiling support thôi. Bởi cho dù tôi có cố đến máy thì cách chuyển đổi – transpiler chỉ là chữa cháy tạm thời thôi. Thế nên trong tương lai không xa thì Pinecone sẽ có sự thay đổi về mặt này.
Lời kết
Hi vọng là bài viết giúp bạn hiểu rõ thêm về ngôn ngữ lập trình. Tôi cũng khuyến khích các bạn thử viết cho mình một ngôn ngữ lập trình riêng. Sau đây là những kinh nghiệm đúc kết được của tôi:
- Khi bạn còn đang hòai nghi thì cứ chọn interpreted. ngôn ngữ thông dịch luôn dễ để viết, build cũng như học. Không phải là tôi chê compiled nhưng nếu mà bạn không biết phải chọn gì thì cứ interpreted mà tới.
- Đối với lexer và parser thì cứ “vọc” theo ý bạn. Tại việc tự viết hay sử dụng chương trình có sẵn đều có điểm mạnh điểm yếu của nó. Điều quan trọng là ở bạn.
- Học theo structure “ống nước” của tôi. Đây là kinh nghiệm xương máu mà tôi rút ra được khi viết nên Pinecone vì thế mà bạn hãy làm theo. Chỉ nên bỏ qua nó nếu bạn thật sự có ý tưởng tốt hơn.
- Nếu bạn không có thời gian cũng như động lực để viết một ngôn ngữ lập trình quá phức tạp thì thử xài những ngôn ngữ lập trình như Brainfuck. Đây là những interpreter khá ngắn với vọn vẹn vài trăm dòng code.
Sau một thời gian phát triển Pinecone, mắc rất nhiều lỗi cũng như là dành thời gian để sửa những lỗi đó. Pinecone hiện giờ đã vào giai đoạn hoạt động hiệu quả và vẫn được tiếp tục phát triển. Việc tạo ra Pinecone quả thật đã cho tôi rất nhiều bài học hữu ích cũng như những trải nghiệm khó quên và đối với tôi thì mọi thứ cũng chỉ vừa mới bắt đầu thôi. Sẽ còn nhiều thứ để phải làm.
Nguồn: Techtalk via medium






")
")
")




