

Bài viết đến từ chị Nguyễn Khánh Linh – Quản lý Cao cấp Khoa học dữ liệu
Data Science team @Techcombank
Xây dựng các mô hình Học máy (Machine Learning models) để phục vụ các bài toán của doanh nghiệp hay khách hàng là một trong những công việc quan trọng của khối Dữ liệu và Phân tích (Data & Analytics Division) tại Techcombank. Mọi chuyện tưởng chừng đơn giản nếu chúng ta có ít nhu cầu hay lượng dữ liệu không cần cập nhật nhiều và thường xuyên, hoặc team quy mô nhỏ tới rất nhỏ. Tuy nhiên, khi team lớn dần và nhu cầu từ các bên ngày một nhiều, việc có một hạ tầng để phát triển những mô hình học máy này sẽ trở nên cần thiết.


Việc có một hệ thống về Machine Learning tốt sẽ giúp giải quyết các vấn đề như:
- Cung cấp cho nhà phân tích dữ liệu (Data analyst), nhà khoa học dữ liệu (Data scientist) và kỹ sư học máy (Machine learning engineer) một công cụ để cùng xử lý dữ liệu và phát triển thuật toán hay mô hình một cách thuận tiện, nhanh chóng.
- Tích hợp kèm với một kho thuộc tính (Feature/attribute store) để lưu trữ, tái sử dụng, và phát triển thêm các thuộc tính mới một cách tập trung để cải tiến mô hình.
- Kết nối từ đầu tới cuối (end-to-end) cho một quy trình tích hợp, phát triển cũng như triển khai liên tục (CI/CD) các mô hình học máy và code của nó, từ việc xử lý dữ liệu cho tới triển khai mô hình lên vận hành.
- Write Once, Run Everywhere.
Vì vậy, bài viết dưới đây sẽ giới thiệu về Machine Learning platform mà hiện tại Techcombank đang sử dụng on-premise (tại chỗ), hay còn được gọi là Research Environment (RE).
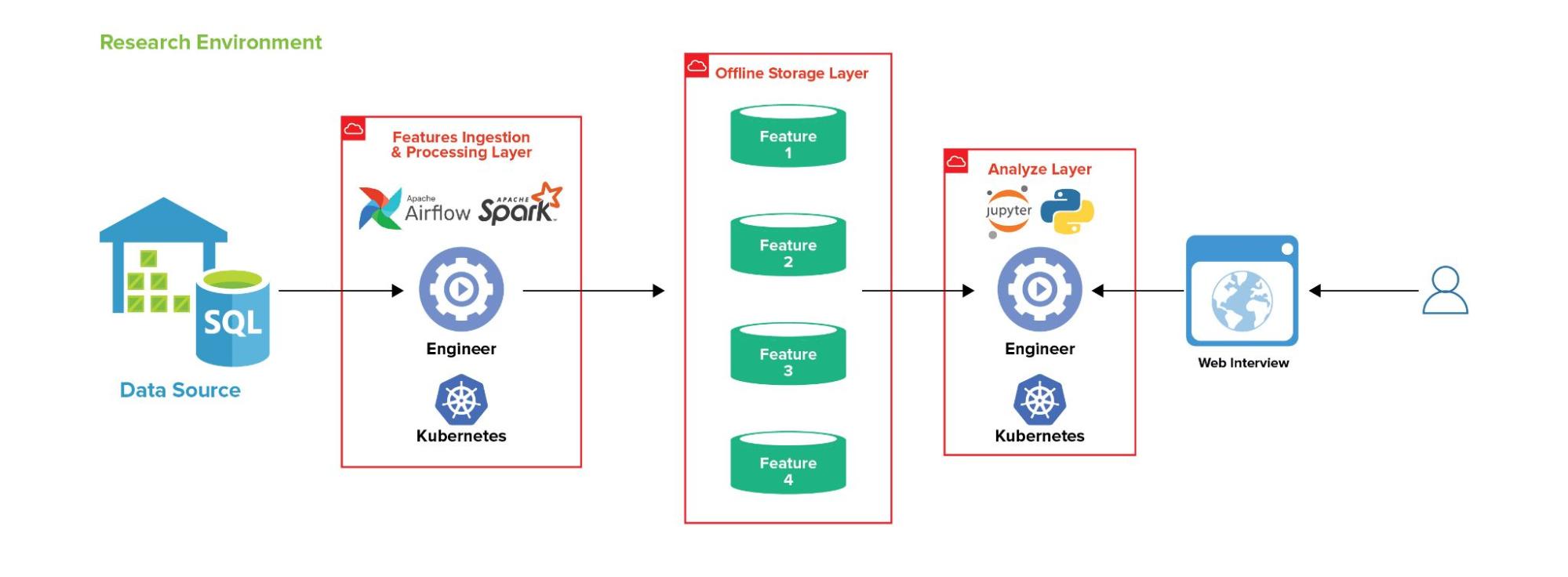
Thiết kế tổng quan
Đầu tiên, người dùng sẽ truy cập hệ thống thông qua Web UI bằng username và password của mình. Hệ thống ML Platform này bao gồm các phần:
- Features Ingestion & Processing Layer: Được dựng bởi Kubernetes và đã được cài đặt Apache Spark và Airflow để giúp tạo các luồng lấy features từ các nguồn dữ liệu (vd: Datawarehouse)
- Offline Storage Layer: Đây là layer chứa các features sau khi được kéo về từ nguồn dữ liệu.
- Analyze Layer: Đây chính là component chính mà người dùng sử dụng và tương tác, đã bao gồm Jupyter Notebook, PySpark được dựng bởi Kubernetes.
Trước mắt để trả lời cho câu hỏi “vì sao dùng Kubernetes cho ML Platform”, hãy cùng tìm hiểu về Kubernetes là gì và cấu trúc của nó thế nào nhé.
Cấu trúc và mục đích sử dụng của Kubernetes (hay còn gọi là K8s)
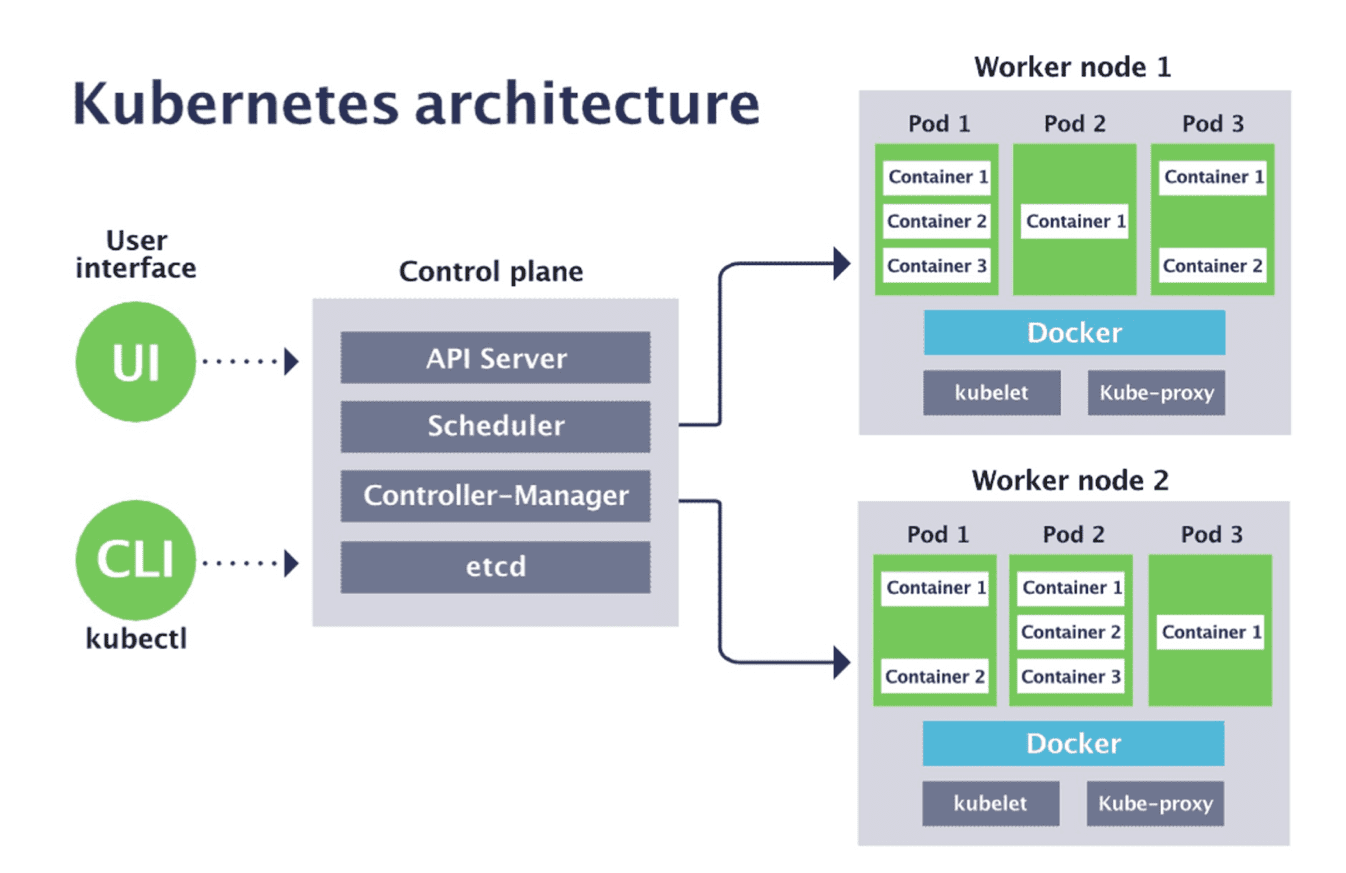
Kubernetes là một nền tảng mã nguồn mở, di động, có thể mở rộng để quản lý khối lượng công việc và dịch vụ được chứa trong container, hỗ trợ cả cấu hình khai báo và tự động hóa. Đây là một giải pháp tốt để đóng gói và chạy các ứng dụng của bạn với môi trường riêng biệt. Nó cung cấp cho chúng ta một framework để chạy các hệ thống phân tán một cách linh hoạt. Kubernetes có khả năng đảm nhiệm việc mở rộng quy mô và chuyển đổi dự phòng cho ứng dụng của bạn, cung cấp các mẫu deploy một các nhanh nhất.
Vì vậy, khi xem xét đến use-case của một ngân hàng như Techcombank, quy mô team Data Science có thể lớn tới hàng chục thậm chí cả trăm người thì đây là giải pháp thích hợp nhất. Mỗi một Data Scientist hay Data Analyst đều có thể tự khởi tạo một môi trường riêng của mình, chạy các ứng dụng, cài đặt thư viện hay phát triển mô hình hoặc code trên đó mà không làm ảnh hưởng đến người dùng khác.
Features Ingestion & Processing Layer
Đây là layer phụ trách việc lấy dữ liệu ban đầu, xử lý qua các trường dữ liệu và thuộc tính một cách tự động.
Hàng tháng, hàng tuần hoặc hàng ngày, dữ liệu phải được ETL (Extract, Transform, Load) từ kho dữ liệu đến một nơi chứa, ví dụ Hadoop. Hiện tại, ML Platform đang cài đặt Airflow để giúp ETL tự động các dữ liệu này. Các bước để tự động hoá luồng ETL dữ liệu như sau:
- Code của bạn phải là code chạy được (executable code/program file), bao gồm input, output rõ ràng và không phải là file notebook. Bạn cần test trước trên máy cá nhân để chắc chắn rằng file code này chạy được và chạy đúng. Code mẫu cho file ETL có thể trông như sau:
config = utils.get_config_spark('etl_table', local=False, user='airflow', driver_mem='4g', driver_core='4', instances='3', executor_mem='4', executor_core='3', message=256, maxResultSize='32g') spark = utils.get_spark_session(config=config) TIME_FORMAT = "%Y%m%d" options = { "use_secret": True, "reader": "spark", "writer": "spark", "mode": "daily", 'n_partition': 200, 'output_pattern': "/path/to/output/upto_date={}", 'query': etl_params['data_txn_query'], 'source': 'your_data_source', 'partition_column': etl_params['data_txn_partition_column'], 'spark': spark, 'spark_schema': etl_params['data_txn_schema_spark'], 'pandas_schema': etl_params['data_txn_schema_pandas'] } if __name__ == "__main__": today = (datetime.date.today() + datetime.timedelta(hours=7) - datetime.timedelta(days=2)).strftime('%Y%m%d') etl_table.run_ETL_raw([today], options=options)
Ta có thể có một file code khác để gộp các files nhỏ như ở trên cho các bảng khác nhau, sau đó dùng chúng để biến đổi và gộp. Ví dụ:
dag_monthly = DAG( dag_id="etl_monthly", description="etl monthly", schedule_interval="0 0 9 * *", default_args=default_args, catchup=False, ) etl_src_1 = kubernetes_pod_etl(arguments=[f"path/to/etl/src1.py"], task_id=" etl_src_1", dag=dag_monthly) etl_src_2 = kubernetes_pod_etl(arguments=[f"path/to/etl/src2.py"], task_id=" etl_src_2", dag=dag_monthly) etl_src_3 = kubernetes_pod_etl(arguments=[f"path/to/etl/src3.py"], task_id=" etl_src_3", dag=dag_monthly) etl_src_1 >> etl_src_2 >> etl_src_3
2. Bạn cần có quyền kết nối vào các data sources cần thiết để lấy dữ liệu về. Ví dụ:
os.environ.get('user_{your_db}') os.environ[‘PASSWORD’] os.environ[‘USERNAME’]
3. Viết và commit DAGs file vào Git repo, sau đó file sẽ được tự động deployed vào Airflow thông qua ArgoCD. Ví dụ như hình dưới đây.
Sau đó, những file DAG sẽ được Airflow tự động chạy (execute) và tự kéo dữ liệu hay features về Offline Storage Layer.
Offline Storage Layer
Offline Storage Layer (Tầng lưu trữ dữ liệu ngoại tuyến) là nơi lưu trữ những features sau khi đã được biến đổi logic để phù hợp với việc phân tích dữ liệu. Tầng lưu trữ dữ liệu cũng được dựng lên bởi Kubernetes, là một nơi lưu trữ centralized cho cả team Data Scientist. Features được tập trung với mục đích:
- Thống nhất định nghĩa, logic về features giữa các team
- Tránh việc phát triển trùng lặp features
- Tái sử dụng những features được phát triển của team khác, tiết kiệm thời gian, tài nguyên
Để đảm bảo tính reliability và fault-tolerant cho tầng lưu trữ dữ liệu này, hệ thống Hadoop Distributed Filesystem (HDFS) được sử dụng. HDFS hỗ trợ việc replication và partition dữ liệu một cách tự động. Cụ thể hơn về HDFS, mời các bạn tham khảo tài liệu chính thức từ Apache.
Sau khi dữ liệu được lưu trữ lên HDFS, những thành viên trong team có thể truy cập để lấy và sử dụng dữ liệu một cách đơn giản thông qua câu lệnh hdfs dfs -get. HDFS được dựng trên một pod của Kubernetes và mọi người trong team Data Scientist có thể access pod và lấy dữ liệu về sử dụng cho Analyze Layer.
Analyze Layer
Analyze Layer (Tầng phân tích), tương tự với tầng Features Ingestion, cũng được dựng lên bởi Kubernetes. Analyze Layer là tầng cuối trong thiết kế hệ thống phân tích dữ liệu On-premises của Techcombank, nơi Data Scientist phân tích, tối đa hoá giá trị của dữ liệu mang lại cho từng bài toán cụ thể.
Về mặt dữ liệu, như đã trình bày ở trên, sau khi dữ liệu nguồn được biến đổi thành features dễ sử dụng, Data Scientist có thể truy cập từ một nguồn feature thống nhất của team với số lượng feature lên tới gần 1000. Data Scientist hoàn toàn có thể phát triển thêm và làm giàu cho hệ thống lưu trữ này.
Về mặt phần cứng và sức mạnh xử lý cho từng người dùng, với sự hỗ trợ từ Kubernetes, người dùng có thể tự tạo workspace với nguyện vọng phần cứng về số nhân CPU, GPU, RAM, volume phù hợp và Kubeflow sẽ tìm cách phân bổ phần cứng phù hợp. Về mặt thư viện, để đảm bảo tính bảo mật với thư viện mã nguồn mở, những thư viện, docker image được cài lên hệ thống cần phải được kiểm duyệt trước khi sử dụng, thông qua Nexus.
Với sự kết hợp của phần cứng, thư viện và dữ liệu, Data Scientist giờ đây đã được cung cấp một môi trường làm việc với đầy đủ công cụ để phát triển mô hình.
Monitoring
Tất nhiên, việc triển khai hệ thống On-premises sẽ gặp những sự cố không đáng có về mặt phần cứng hay sai sót trong quản lý phần mềm. Đó là lý do chúng ta cần một hệ thống giám sát thông số, performance metrics để dễ dàng trace back trong trường hợp sự cố xảy ra. Những thông số kỹ thuật này được generate thông qua Prometheus và sau đó được trực quan hoá bằng Grafana dashboard. Những câu hỏi thường gặp của Data Scientist mà Grafana có thể cung cấp câu trả lời là:
- Tại sao code chạy mãi mà cứ quay hoài?
=> lỗi thường gặp là do tràn RAM, check thông số về tỉ lệ giữa RAM sử dụng thực tế và RAM được cung cấp. Nếu do lỗi tràn RAM, có thể cần cung cấp thêm RAM cho người dùng, hoặc người dùng tìm cách để tối ưu hoá code của mình
– Sao không xóa được file này nhỉ?
=> lỗi thường gặp là do hết ROM và interface trên jupyter lab không xoá triệt để những dữ liệu cũ. Kiểm tra bằng việc xem thông số về bộ nhớ.

Các cơ hội việc làm tại Techcombank

Bài viết liên quan

Khoa học dữ liệu - Đòn bẩy cho Ngân hàng 4.0 toàn diện

