

Trong machine learning, có một thứ gọi là định luật ” No Free Lunch “. Nói một cách ngắn gọn, điều đó cho rằng không có một thuật toán nào là tốt nhất trong mọi vấn đề và nó đặc biệt phù hợp với supervised learning – việc học dưới sự giám sát ( ví dụ là predictive modeling – mô hình tiên đoán).
Ví dụ, bạn không thể nói rằng các kết nối nơ-ron luôn tốt hơn cây quyết định – decision trees (hay ngược lại). Có rất nhiều yếu tố ảnh hưởng chẳng hạn như kích thước và cấu trúc của bộ dữ liệu.
Do đó, bạn nên thử nhiều thuật toán khác nhau cho vấn đề của bạn, trong khi sử dụng một “ tập kiểm tra ” còn lại để đánh giá hiệu suất và chọn ra giải pháp tối ưu nhất.

Tất nhiên, các thuật toán bạn thử phải phù hợp với vấn đề của bạn, đó là việc bạn chọn đúng công việc cho machine learning. Tương tự, nếu bạn cần dọn dẹp nhà cửa, bạn có thể sử dụng máy hút bụi, một cây chổi hoặc một cái giẻ lau, nhưng bạn sẽ không sử dụng một cái xẻng và đào.
The Big Principle
Tuy nhiên, có một nguyên tắc chung là cơ sở cho mọi thuật toán machine learning được giám sát cho mô hình tiên đoán.
Các thuật toán machine learning được mô tả như việc học một target function (f) để biến bản đồ đầu vào (X) thành biến xuất (Y): Y = f (X)
Đây là một nhiệm vụ học tập tổng quát mà chúng ta muốn đưa ra những tiên đoán trong tương lai (Y) với các ví dụ mới về các biến đầu vào (X). Chúng ta không biết chức năng (f) trông như thế nào hoặc dạng của nó. Nếu chúng ta làm như vậy, chúng ta sẽ sử dụng nó trực tiếp và không cần phải học nó từ dữ liệu bằng cách sử dụng các thuật toán machine learning.
Phương thức phổ biến nhất của machine learning là học cách lập bản đồ Y = f (X) để đưa ra dự đoán của Y cho biến X mới. Điều này được gọi là mô hình tiên đoán hoặc phân tích tiên đoán và mục tiêu của chúng ta là làm cho các dự đoán chính xác nhất có thể được.
Đối với những người mới học về machine learning muốn hiểu được cơ bản của nó, đây sẽ là một chuyến khám phá nhanh về 10 thuật toán machine learning hàng đầu được các nhà khoa học dữ liệu sử dụng.
1. Linear Regression – Hồi quy tuyến tính
Hồi quy tuyến tính có lẽ là một trong những thuật toán nổi tiếng nhất và được hiểu rõ nhất trong thống kê và machine learning.
Mô hình tiên đoán chủ yếu quan tâm đến việc giảm thiểu sai sót của mô hình hoặc đưa ra các dự đoán chính xác nhất có thể, với một chi phí giải trình. Chúng tôi sẽ mượn, sử dụng lại và lấy các thuật toán từ nhiều lĩnh vực khác nhau, bao gồm số liệu thống kê và sử dụng chúng cho những mục đích này.
Biểu diễn hồi quy tuyến tính là một phương trình mô tả một đường thẳng mô tả phù hợp nhất mối quan hệ giữa các biến đầu vào (x) và các biến đầu ra (y), bằng cách tìm các trọng số cụ thể cho các biến đầu vào được gọi là các hệ số (B).
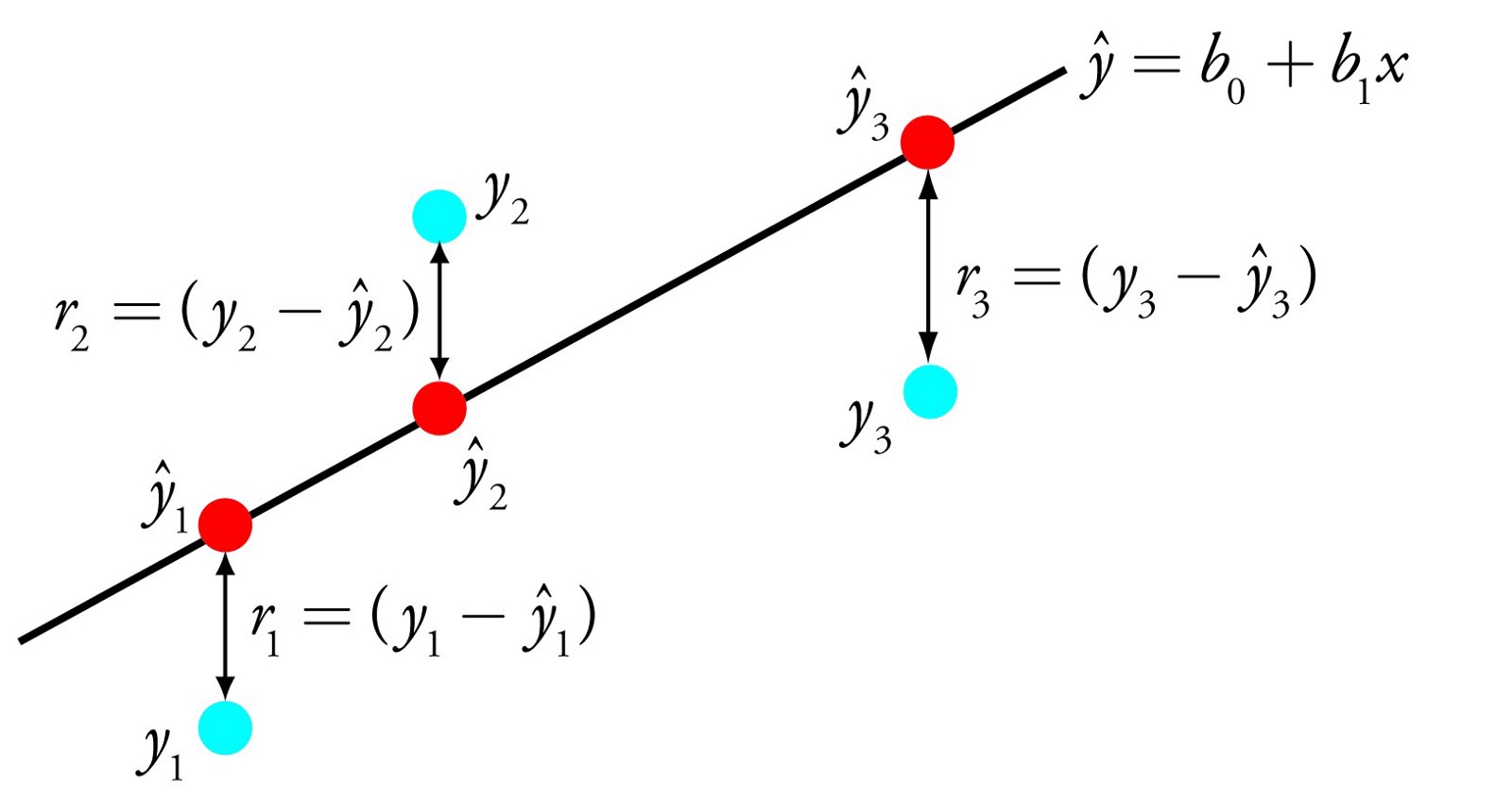
Ví dụ: y = B0 + B1 * x
Chúng ta sẽ dự đoán y với biến x cho trước và mục tiêu của thuật toán hồi quy tuyến tính là tìm các giá trị cho các hệ số B0 và B1.
Các kĩ thuật khác nhau có thể được sử dụng để tìm mô hình hồi quy tuyến tính từ dữ liệu, chẳng hạn như một giải pháp đại số tuyến tính cho Ordinary least square và việc tối ưu hóa Gradient descent.
Hồi quy tuyến tính đã được phát minh khoảng hơn 200 năm và đã được nghiên cứu rộng rãi. Một số quy tắc tốt khi sử dụng kĩ thuật này là loại bỏ các biến tương tự nhau (correlated) và để loại bỏ bớt yếu tố sao lãng từ dữ liệu của bạn, nếu có thể. Đây là một kĩ thuật đơn giản và nhanh chóng, và là thuật toán tốt đầu tiên để thử.
2. Logistic Regression – Hồi quy logistic
Hồi quy logistic là một thuật toán khác được mượn bởi machine learning từ lĩnh vực thống kê. Đây là phương thức tốt nhất cho các vấn đề phân loại nhị phân (vấn đề với hai lớp giá trị).
Hồi quy logistic giống như hồi quy tuyến tính với mục đích là để tìm ra các giá trị cho các hệ số mà trọng lượng mỗi biến đầu vào. Không giống như hồi quy tuyến tính, dự đoán đầu ra được chuyển đổi bằng cách sử dụng một hàm không tuyến tính được gọi là hàm logistic.
Hàm logistic trông giống như một S lớn và sẽ biến đổi bất kỳ giá trị nào thành 0-1. Điều này rất hữu ích bởi vì chúng ta có thể áp dụng một quy tắc cho đầu ra của hàm logistic để tăng giá trị cho 0 và 1 (ví dụ IF ít hơn 0.5 sau đó đầu ra 1) và dự đoán một lớp giá trị.
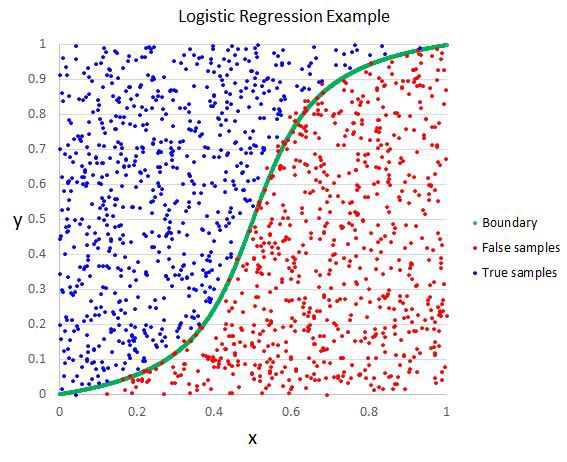
Vì cách mô hình được học, các dự đoán thực hiện bởi hồi quy logistic cũng có thể được sử dụng như là xác suất của một ví dụ dữ liệu nhất định thuộc lớp 0 hoặc lớp 1. Điều này có thể hữu ích cho các vấn đề khi bạn cần đưa ra nhiều lý do cho một dự đoán.
Giống như hồi quy tuyến tính, hồi quy logistic hoạt động tốt hơn khi bạn loại bỏ các thuộc tính không liên quan đến biến đầu ra cũng như các thuộc tính tương tự nhau (correlated). Đó là một mô hình có thể học hỏi nhanh và có hiệu quả với các vấn đề phân loại nhị phân.
Tham khảo thêm các bài viết về Machine learning:
3. Linear Discriminant Analysis – Phân tích phân loại tuyến tính
Hồi quy Logistic là một thuật toán phân loại truyền thống giới hạn vào các vấn đề phân loại hai lớp. Nếu bạn có nhiều hơn hai lớp thì thuật toán phân tích phân loại tuyến tính nên được ưu tiên.
Sự biểu hiện của LDA khá đơn giản. Nó bao gồm các thuộc tính thống kê của dữ liệu của bạn, được tính cho mỗi lớp. Đối với một biến đầu vào duy nhất, nó bao gồm:
- Giá trị trung bình cho mỗi lớp.
- Phương sai được tính trên tất cả các lớp.
Dự đoán được thực hiện bằng cách tính giá trị phân biệt cho mỗi lớp và dự đoán cho lớp đó có giá trị lớn nhất. Kĩ thuật giả định rằng dữ liệu có một phân bố Gaussian (bell curve), do đó tốt hơn là bạn nên loại bỏ các giá trị ngoại vi khỏi dữ liệu của bạn trước. Đây là một phương pháp đơn giản và mạnh mẽ để phân loại các vấn đề mô hình dự báo.
4. Classification and regression trees – Cây phân loại và hồi quy
Decision trees là một loại thuật toán quan trọng cho mô hình tiên đoán machine learning.
Sự biểu diễn của mô hình decision tree là một cây nhị phân. Đây là cây nhị phân của bạn từ các thuật toán và cấu trúc dữ liệu, không có gì quá ưa thích. Mỗi node đại diện cho một biến đầu vào duy nhất (x) và một điểm phân chia trên biến đó (giả sử biến đó là số).
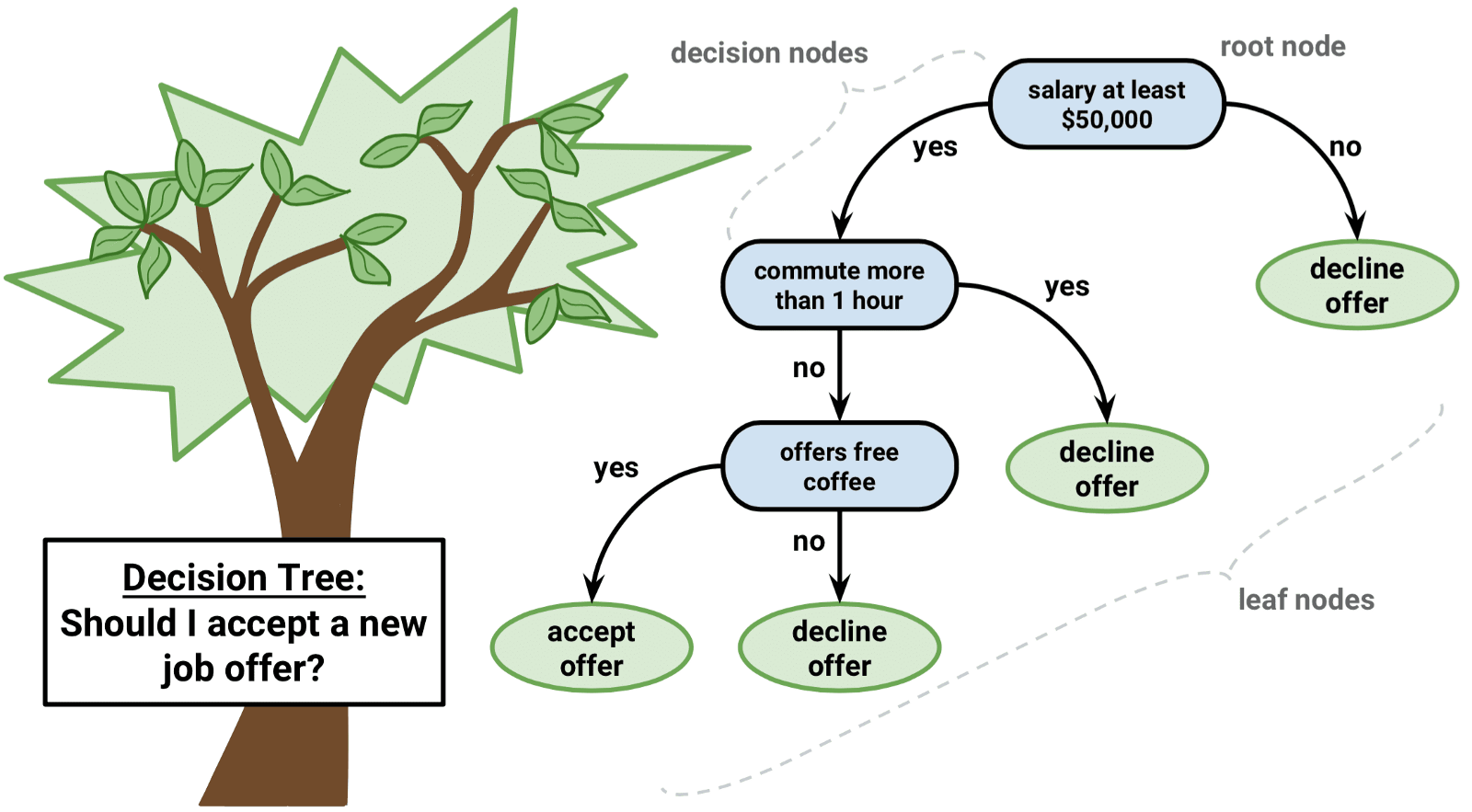
Các node lá của cây chứa một biến đầu ra (y) được sử dụng để dự đoán. Các tiên đoán được thực hiện bằng cách đi trên các nhánh của cây cho đến khi đến một node lá và đưa ra lớp giá trị tại node lá đó.
Cây có thể học rất nhanh và có thể dùng để dự đoán rất nhanh. Chúng thường chính xác cho nhiều loại vấn đề và dữ liệu của bạn không cần bất kỳ sự chuẩn bị đặc biệt nào.
Tham khảo thêm: Tuyển lập trình viên Machine Learning lương cao
5. Naive Bayes
Naive Bayes là một thuật toán đơn giản nhưng mạnh mẽ về mô hình tiên đoán.
Mô hình bao gồm hai loại xác suất có thể được tính trực tiếp từ dữ liệu của bạn:
1) Xác suất của mỗi lớp;
2) Xác suất có điều kiện cho mỗi lớp với mỗi giá trị x.
Sau khi tính, mô hình xác suất có thể được sử dụng để đưa ra dự đoán cho dữ liệu mới bằng Định lý Bayes. Khi dữ liệu của bạn có giá trị thực, giả sử một phân phối Gaussian (bell curve) khá phổ biến nên bạn có thể dễ dàng ước tính được các xác suất này.
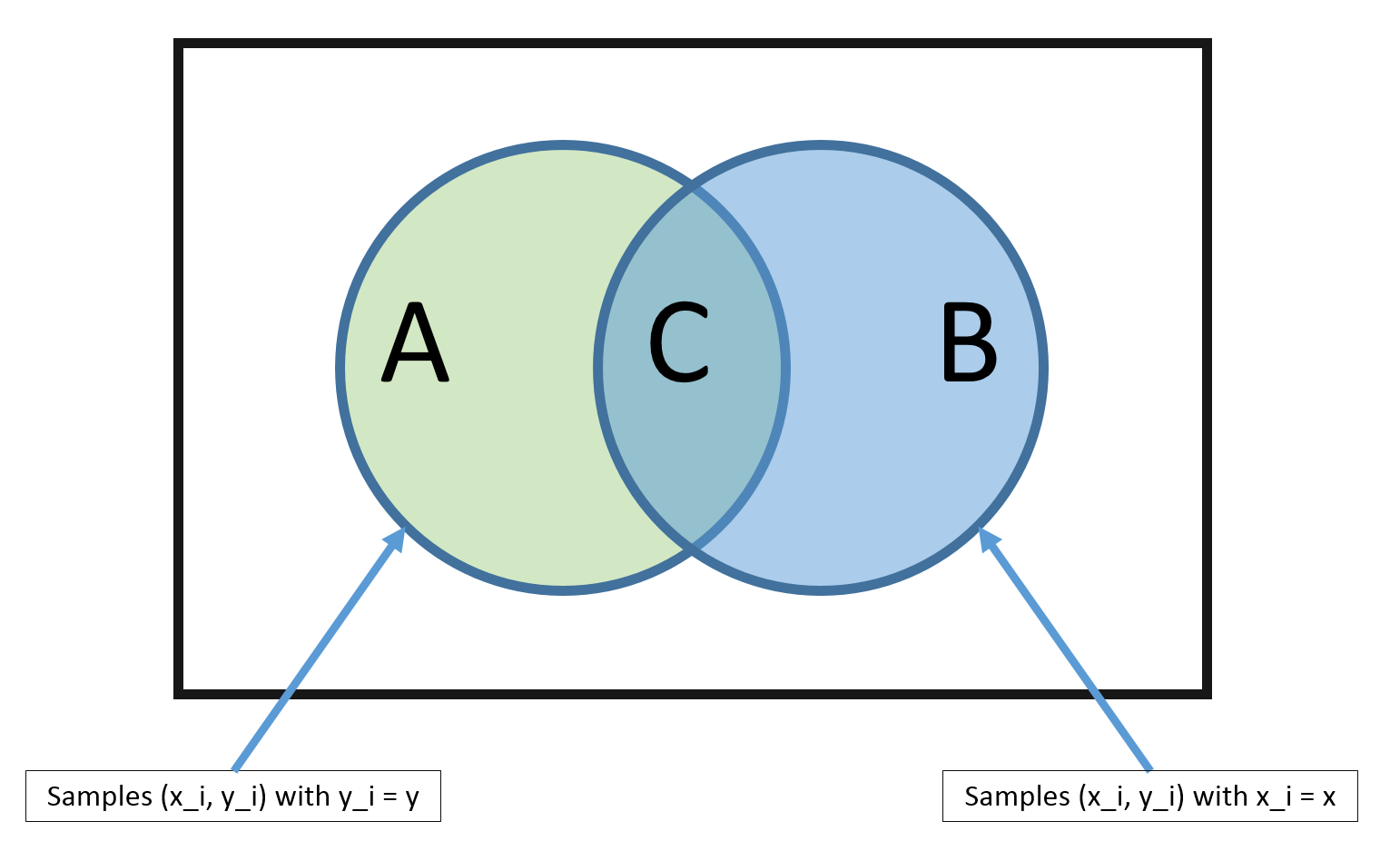
Naive Bayes được gọi là naive vì nó giả định rằng mỗi biến đầu vào là độc lập. Đây là một giả định mạnh mẽ và không thực tế đối với dữ liệu thực, tuy nhiên, kĩ thuật này rất hiệu quả trên một phạm vi rộng lớn với các vấn đề phức tạp.
6. K – Nearest Neighbors – KNN
Thuật toán KNN rất đơn giản và rất hiệu quả. Mô hình đại diện cho KNN là toàn bộ dữ liệu tập huấn. Đơn giản phải không?
Dự đoán được thực hiện cho một điểm dữ liệu mới bằng cách tìm kiếm thông qua toàn bộ tập đào tạo cho hầu hết các ví dụ K giống nhau (hàng xóm) và tóm tắt biến đầu ra cho các ví dụ K. Đối với các vấn đề hồi quy, đây có thể là biến đầu ra trung bình, đối với các vấn đề phân loại, đây có thể là mode (hoặc phổ biến nhất) của lớp.
Bí quyết là làm thế nào để xác định sự giống nhau giữa các trường hợp dữ liệu. Kĩ thuật đơn giản nhất nếu các thuộc tính của bạn có cùng kích cỡ (ví dụ tất cả đều là inch) là sử dụng khoảng cách Euclide, một con số bạn có thể tính toán trực tiếp dựa trên sự khác biệt giữa mỗi biến đầu vào.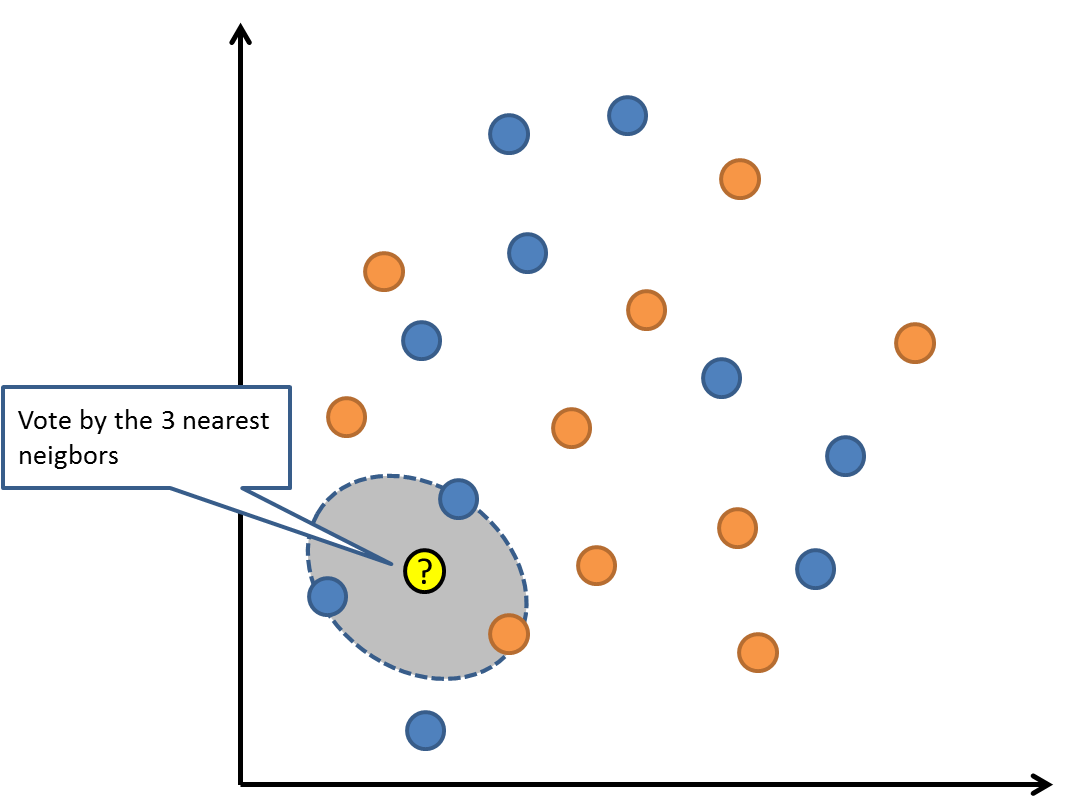 có thể yêu cầu rất nhiều bộ nhớ hoặc không gian để lưu trữ tất cả dữ liệu, nhưng chỉ thực hiện tính toán (hoặc học) khi một dự báo là cần thiết, chỉ vừa đúng lúc. Bạn cũng có thể cập nhật và tổ chức các bài tập đào tạo theo thời gian để giữ các dự đoán chính xác.
có thể yêu cầu rất nhiều bộ nhớ hoặc không gian để lưu trữ tất cả dữ liệu, nhưng chỉ thực hiện tính toán (hoặc học) khi một dự báo là cần thiết, chỉ vừa đúng lúc. Bạn cũng có thể cập nhật và tổ chức các bài tập đào tạo theo thời gian để giữ các dự đoán chính xác.
Ý tưởng về khoảng cách hoặc độ gần có thể bị phá vỡ với các quy mô rất cao (rất nhiều biến đầu vào) có thể ảnh hưởng tiêu cực đến hiệu suất của thuật toán đối với vấn đề của bạn. Đây được gọi là lời nguyền của quy mô. Nó cho thấy bạn chỉ sử dụng những biến đầu vào có liên quan nhất đến dự đoán biến đầu ra.
7. Học Vector Quantization
Nhược điểm của K- Nearest Neighbors là bạn cần phải giữ nguyên bộ dữ liệu đào tạo của mình. Thuật toán Quantization về Vector (hay LVQ) là một thuật toán mạng thần kinh nhân tạo cho phép bạn chọn có bao nhiêu trường hợp đào tạo để treo lên và tìm hiểu chính xác những trường hợp này sẽ như thế nào.
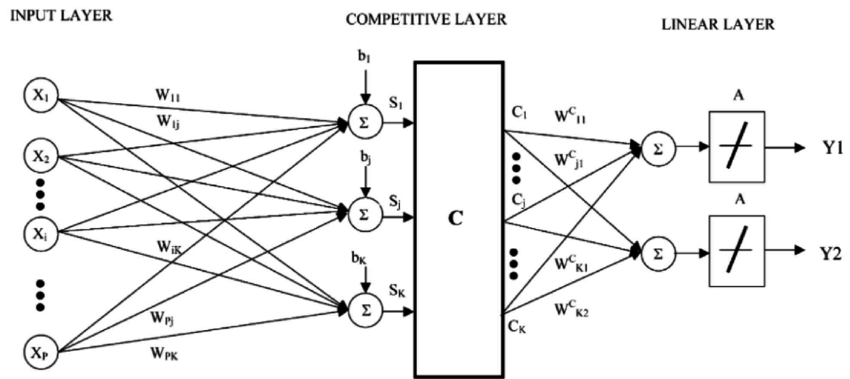
Sự biểu diễn cho LVQ là một tập hợp các codebook vector. Chúng được lựa chọn ngẫu nhiên từ đầu và thích nghi để tóm tắt tốt nhất tập dữ liệu đào tạo qua một số lần lặp của thuật toán. Sau khi học được, các vector mã có thể được sử dụng để tạo ra các dự đoán giống như K- Nearest Neighbors. Các hàng xóm tương tự nhất ( phù hợp với codebook vector nhất ) được tìm thấy bằng cách tính toán khoảng cách giữa mỗi vector và ví dụ dữ liệu mới. Lớp giá trị hoặc (giá trị thực trong trường hợp hồi quy) cho đơn vị kết hợp tốt nhất sau đó sẽ được trả về như dự đoán. Kết quả tốt nhất đạt được khi bạn thay đổi dữ liệu của mình để có cùng phạm vi, chẳng hạn như giữa 0 và 1.
Nếu bạn phát hiện ra rằng KNN mang lại kết quả tốt trên tập dữ liệu của bạn, hãy thử sử dụng LVQ để giảm yêu cầu về bộ nhớ để lưu trữ toàn bộ tập dữ liệu đào tạo.
8. Support Vector machines
Support vector machines có lẽ là một trong những thuật toán machine learning phổ biến nhất và được nói về nhiều nhất.
Một hyperplane là một đường phân chia không gian biến đầu vào. Trong SVM, một hyperplance được chọn để phân tách tốt nhất các điểm trong không gian các biến đầu vào theo lớp của chúng, hoặc là lớp 0 hoặc lớp 1. Trong hai chiều, bạn có thể hình dung nó như một đường thẳng và giả sử rằng tất cả các biến đầu vào của chúng ta có thể được tách hoàn toàn bằng dòng này. Thuật toán SVM tìm ra các hệ số dẫn đến sự phân tách tốt nhất của các lớp theo hyperplance.
 Khoảng cách giữa hyperplane và điểm dữ liệu gần nhất được gọi là biên. Hyperplane tốt nhất hoặc tối ưu có thể tách riêng hai lớp là dòng có biên lớn nhất. Chỉ những điểm này có liên quan đến việc xác định hyperplane và trong việc xây dựng các điểm phân loại. Những điểm này được gọi là các vector hỗ trợ. Chúng hỗ trợ hoặc xác định hyperplane. Trong thực tế, một thuật toán tối ưu được sử dụng để tìm các giá trị cho các hệ số tối đa hóa biên.
Khoảng cách giữa hyperplane và điểm dữ liệu gần nhất được gọi là biên. Hyperplane tốt nhất hoặc tối ưu có thể tách riêng hai lớp là dòng có biên lớn nhất. Chỉ những điểm này có liên quan đến việc xác định hyperplane và trong việc xây dựng các điểm phân loại. Những điểm này được gọi là các vector hỗ trợ. Chúng hỗ trợ hoặc xác định hyperplane. Trong thực tế, một thuật toán tối ưu được sử dụng để tìm các giá trị cho các hệ số tối đa hóa biên.
SVM có thể là một trong những phương pháp phân loại hàng đầu mạnh mẽ nhất và đáng thử trên tập dữ liệu của bạn.
9. Bagging and Random Forest
Random Forest là một trong những thuật toán machine learning phổ biến nhất và mạnh nhất. Nó là một loại thuật toán machine learning được gọi là Bootstrap Aggregation hoặc Bagging.
Bootstrap là một phương pháp thống kê mạnh mẽ để ước lượng số lượng từ một mẫu dữ liệu. Chẳng hạn như một giá trị trung bình. Bạn lấy rất nhiều mẫu dữ liệu của bạn, tính giá trị trung bình, sau đó trung bình tất cả các giá trị trung bình của bạn để bạn ước lượng tốt hơn giá trị trung bình thật sự.
Trong bagging, cách tiếp cận tương tự được sử dụng, nhưng thay vì để ước lượng toàn bộ mô hình thống kê, thường là decision trees. Nhiều mẫu dữ liệu đào tạo của bạn được lấy sau đó các mô hình được xây dựng cho mỗi mẫu dữ liệu. Khi bạn cần dự đoán dữ liệu mới, mỗi mô hình sẽ dự đoán và các dự đoán được tính trung bình để ước lượng tốt hơn giá trị đầu ra thật sự.
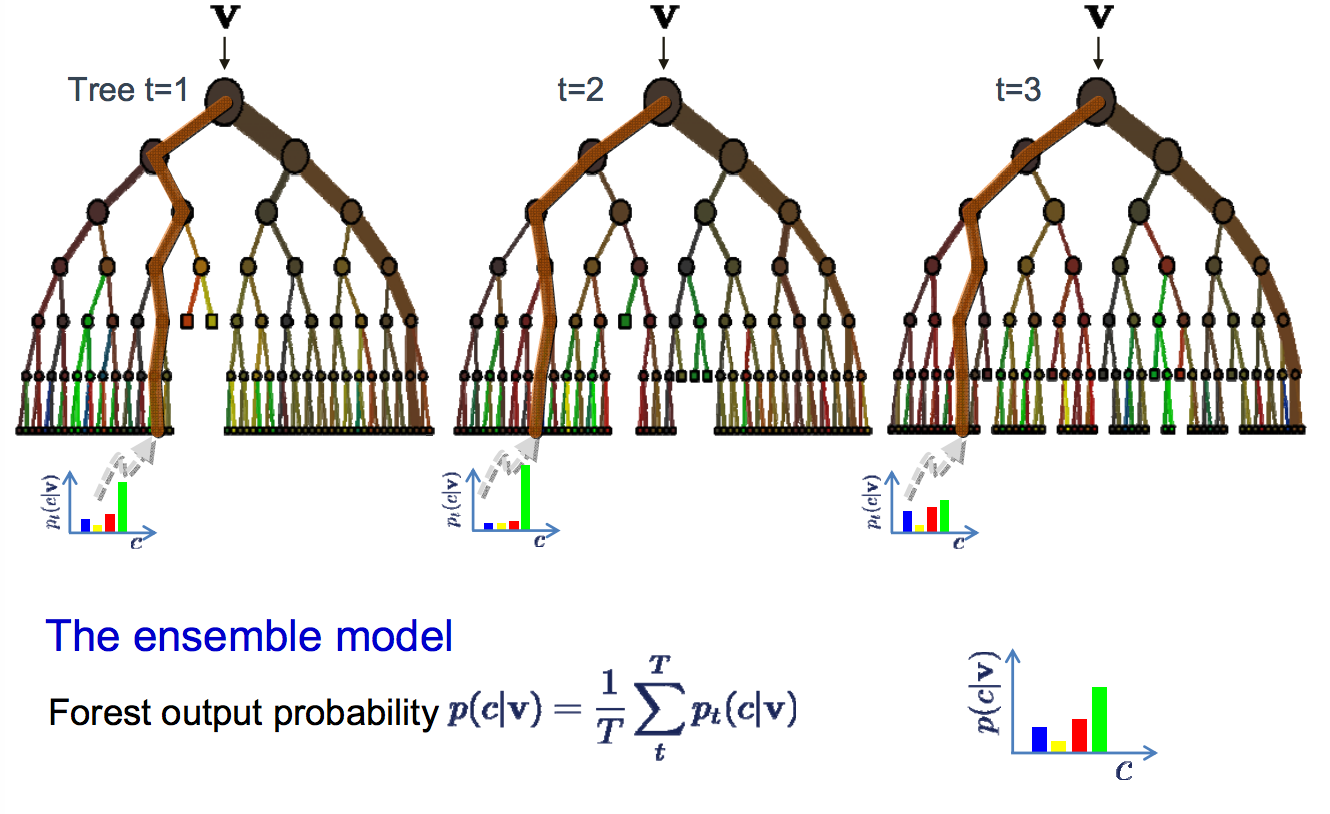
Random forest là một sự tinh chỉnh trên phương pháp tiếp cận này, nơi các decision trees được tạo ra để thay vì chọn các điểm phân chia tối ưu, việc phân chia tối ưu được thực hiện bằng cách đưa ra sự ngẫu nhiên.
Các mô hình được tạo cho mỗi mẫu dữ liệu khác biệt nhiều so với chúng lẽ ra phải như thế, tuy nhiên vẫn chính xác theo những cách độc đáo và khác biệt. Kết hợp dự đoán của chúng dẫn đến một ước tính tốt hơn về giá trị đầu ra cơ bản.
Nếu bạn nhận được kết quả tốt với một thuật toán có độ biến thiên cao (như decision trees), bạn thường có thể nhận được kết quả tốt hơn bằng cách bagging thuật toán đó.
10. Boosting và AdaBoost
Boosting là một kĩ thuật đồng bộ nhằm cố gắng tạo ra một phương pháp phân loại mạnh từ một số phương pháp phân loại yếu. Điều này được thực hiện bằng cách xây dựng mô hình từ dữ liệu đào tạo, sau đó tạo ra một mô hình thứ hai cố gắng sửa lỗi từ mô hình đầu tiên. Các mô hình được thêm vào cho đến khi tập đào tạo được dự đoán hoàn hảo hoặc thêm một số mô hình tối đa.
AdaBoost là thuật toán boosting thành công đầu tiên được phát triển để phân loại nhị phân. Đây là điểm khởi đầu tốt nhất để hiểu về boosting. Các phương pháp boosting hiện đại xây dựng trên AdaBoost, đáng chú ý nhất là các máy boosting gradient ngẫu nhiên.
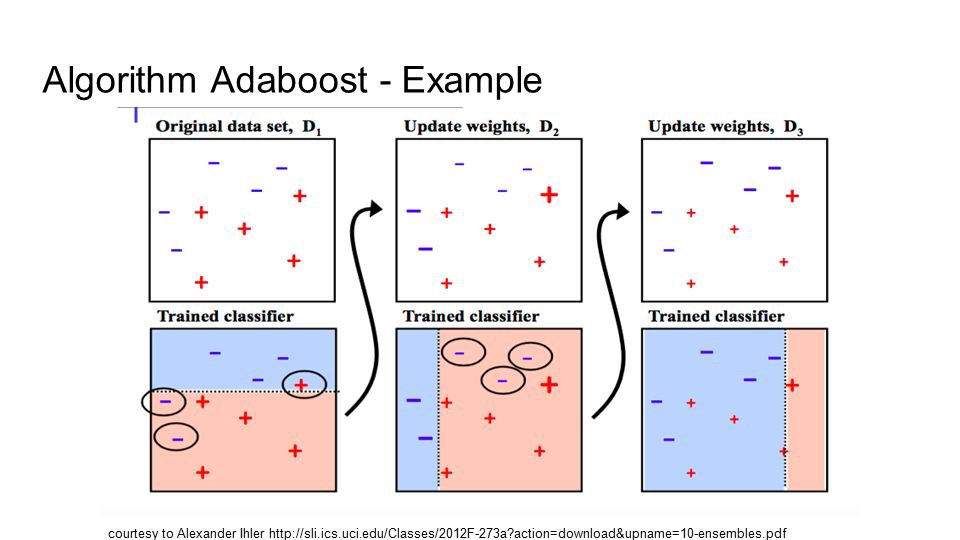
AdaBoost được sử dụng với các decision trees ngắn. Sau khi cây đầu tiên được tạo ra, hiệu suất của cây trên mỗi trường hợp huấn luyện được sử dụng để đo độ chú ý của cây kế tiếp được tạo nên chú ý đến từng trường hợp đào tạo. Dữ liệu đào tạo khó dự đoán sẽ có trọng lượng hơn, trong khi những trường hợp dễ dự đoán có ít trọng lượng hơn. Các mô hình được tạo theo thứ tự tuần tự, mỗi lần cập nhật các trọng số trên các trường hợp đào tạo ảnh hưởng đến việc học được thực hiện bởi cây kế tiếp trong chuỗi. Sau khi tất cả các cây được xây dựng, dự đoán được thực hiện cho dữ liệu mới, và hiệu suất của mỗi cây được đo lường bằng cách nó đã được về dữ liệu đào tạo.
Bởi vì rất nhiều sự chú ý được đưa ra để sửa sai lầm theo thuật toán, điều quan trọng là bạn phải có dữ liệu sạch với các giá trị biên.
Last Takeaway
Một câu hỏi điển hình được hỏi bởi những người mới bắt đầu, khi phải đối mặt với rất nhiều thuật toán machine learning, là “Tôi nên sử dụng thuật toán nào?” Câu trả lời cho câu hỏi thay đổi tùy thuộc vào nhiều yếu tố, bao gồm:
1) Kích thước, chất lượng và tính chất của dữ liệu;
2) Thời gian tính toán;
3) Tính cấp bách của nhiệm vụ;
4) Bạn muốn làm gì với dữ liệu.
Ngay cả một nhà khoa học dữ liệu giàu kinh nghiệm cũng không thể biết được thuật toán nào sẽ thực hiện tốt nhất trước khi thử các thuật toán khác nhau. Mặc dù có nhiều thuật toán machine learning khác, đây là những thuật toán phổ biến nhất. Nếu bạn là một newbie trong mảng machine learning, đây sẽ là một điểm khởi đầu tốt để tìm hiểu.
Tham khảo thêm: Tuyển lập trình viên Machine Learning lương cao
Topdev via Towardsdatasience





")
")
")





