

Machine Learning đang rất được cộng đồng quan tâm. Theo trang towardsdatascience Sự bão hòa thông tin trên các phương tiện truyền thông, đang che dấu những sự thật đằng sau đó.
Hy vọng bài viết này có thể làm sáng tỏ một số những quan niệm sai lầm về ML. Quan trọng hơn là làm rõ một số quy trình của deep learning cũng như nguyên nhân tại sao nó hoạt động tốt trong một số lĩnh vực như xử lý ngôn ngữ tự nhiên (NLP), nhận diện hình ảnh, và dịch ngôn ngữ trong khi lại không thành công ở những mảng khác.
Deep Learning không phải là phép thuật
Truyền thông thường miêu tả deep learning như là một công thức ma thuật cho tất cả các vấn đề của cuộc sống. Trong thực tế, nó hoàn toàn ngược lại. Hơn nữa, deep learning luôn có những hành vi kỳ lạ mà tới giờ chúng ta vẫn không giải thích hết được.

Bằng cách yêu cầu bằng chứng và lập luận trong quá trình phát triển của mình, bạn có thể xây dựng một framework mạnh mẽ từ hằng hà các mô hình khác nhau.

Mọi thứ đều có mục đích
Một trong những vấn đề đầu tiên mà những người mới hay mắc phải là việc cứ gộp chung LSTM (Long Short-Term Memory) layers, GRU (Gated Recurrent Unit) layer và vài layer lẻ tẻ khác lại với nhau rồi chờ kết quả xảy ra một cách thần kì. Họ cần phải nhận ra rằng deep learning đòi hỏi cách tiếp cận hợp lý hơn nhiều.
Bằng cách áp dụng một phương pháp dựa trên sự tích hợp của dữ liệu, network design và sự tò mò, bạn sẽ tạo ra các kết quả phi thường. Tôi dành thời gian mỗi ngày để đọc các bài báo về những phương pháp mới nhất và liên tục nhìn thấy rất nhiều thiết kế vô cùng thông minh.
Trong deep learning, layer khác nhau có các mục đích khác nhau. Đây là một khái niệm đơn giản mà thường bị quên bởi những người mới biết về deep learning. Hơn nữa, trong khi tôi có thử nghiệm rất nhiều trong quá trình thiết kế, tôi luôn luôn kiểm tra chúng rất kĩ lưỡng.
Cần có một lý do (hoặc ít nhất là một giả thuyết) hợp lý cho việc bạn thêm một yếu tố mới. Nó nên được kiểm tra với một thước đo rõ ràng, và chỉ sau đó tôi mới chấp nhận đưa nó vào phiên bản chính thức. Ngoài ra, bạn nên lựa chọn các mô hình đơn giản thay vì phức tạp nếu chúng đều đạt được những kết quả tương tự. Các hệ thống nhỏ và đơn giản hơn cũng có nghĩa là quá trình đào tạo chúng sẽ nhanh hơn cũng như là kết quả thu được sẽ rất tối ưu.
Có những công cụ mà bạn có thể tạo ra để thử nghiệm những ý tưởng cho network design, và nó sẽ giúp bạn hiểu rõ hơn về bản chất của chúng. Khi bạn làm việc nhiều hơn với Neural Networks, bạn cũng đang bắt đầu nắm rõ hơn về những gì thúc đẩy hành vi của nó đối với một hành động cụ thể. Mọi thứ chỉ thật sự rõ ràng khi bạn có phương pháp đo đạc chính xác.
Quá trình thiết kế
Tôi nghĩ về quá trình thiết kế cũng giống như cách một đứa trẻ cố gắng xây dựng một cái tháp bằng lego. Thử – ghép – thất bại – thử ( luôn luôn test liệu nó có phù hợp không)
Liệu rằng là layer thứ hai có lay? Có nên thay đổi phần cơ cấu không? Sẽ rất hữu ích khi bạn nghĩ đến việc tối ưu hóa lượng mảnh ghép. Bởi quy mô càng nhỏ, thì bạn càng có thể thực hiện nó nhanh hơn cũng như kiểm tra dễ dàng hờn. Vì vậy chỉ thêm khi bạn thật sự cần thiết.
Trong deep learning, một vấn đề có vô số các giải pháp giải quyết – Sự phức tạp có khuynh hướng khiến cho ứng dụng bị “bùng nổ” nhanh chóng, và sự gia tăng yêu cầu phức tạp cũng sẽ dẫn tới gia tăng sự kiểm soát. Ví dụ, một pipeline phân tích dữ liệu thăm dò đơn giản có thể là:
NHẬP DỮ LIỆU → LÀM SẠCH DỮ LIỆU → CHUYỂN DỮ LIỆU → HIỂN THỊ DỮ LIỆU
Mỗi bước trên có thể bao gồm nhiều bước nhỏ khác nhau trong đó. Nếu tôi không đảm bảo chất lượng của các quy trình trước thì toàn bộ hệ thống sẽ thất bại bởi data nhận được sai hoàn toàn. Vì vậy, luôn phải kiểm tra từng bước trong quá trình.
Nói cách khác, phải test tất cả mọi thứ – inputs, outputs, classes, functions. Mục tiêu đặt ra là phải đảm bảo mọi thứ hoạt động tốt dù là độc lập hay cùng nhau. Đây không phải là một ý tưởng đột phá gì, nhưng nó thật sự cần được chỉ ra để mọi người hiểu rõ tầm quan trọng của việc này.
Trong deep learning, tôi bắt đầu bằng cách tạo ra mô hình đơn giản nhất. Khi phải dụng tới task phân loại văn bản, tôi sẽ bắt đầu với phiên bản đơn giản nhất của mô hình Embed-Encode-Attend-Predict.
Sau khi nhìn thấy mô hình nền tảng này hoạt động như thế nào, tôi mới bắt đầu xây dựng dựa trên nó. Có thể là tăng kích thước của các layers ẩn, làm sâu thêm network, hay nhập với các network mới cũng như là thay đổi tags và các dữ liệu số khác. Danh sách cứ thế kéo dài tới gần như là vô tận.
Với từng bước, tôi thử để nó chống lại mô hình ban đầu của mình. Quá trình này cho phép tôi nhìn lại sự thay đổi của mô hình, hiểu được nó tốt hơn ở đâu và đưa ra các thay đổi phù hợp cho phiên bản tương lai cũng như đạt tiêu chuẩn đặt ra.
Hãy làm chủ dữ liệu của bạn
Trước khi bạn bắt đầu thử nghiệm với mô hình deep learning của mình, bạn cần hiểu rõ giá trị của nó nằm ở đâu. Có một hệ thống phân chia cấp bậc đơn giản như sau:
Dữ liệu quan trọng hơn model design, và model design quan trọng hơn tối ưu hóa thông số.
Nếu công ty A có mười lần dữ liệu của công ty B, không có mô hình nào trong thế giới này sẽ cho phép công ty B vượt mặt công ty A. Điều này cũng tương tự với chất lượng dữ liệu.
Nếu tôi dành hàng tuần để phát triển mô hình dựa trên dữ liệu có chất lượng thấp, nó sẽ kém hơn mô hình mà tôi đã xây dựng trong vài ngày sau khi có dữ liệu chất lượng cao. Luôn tự hỏi rằng liệu mình có thể nhận được nhiều dữ liệu hơn hay không trước khi dành thời gian cho việc tạo mô hình. Có lẽ bạn có thể thay đổi các bước tiền xử lý để nâng cao chất lượng dữ liệu. Điều này thường dẫn đến hiệu suất nhanh hơn so với việc chỉ điều chỉnh mô hình thôi.
Bạn không chỉ cần dữ liệu có chất lượng cao, mà bạn cũng cần phải hiểu rõ về nó. Bạn nên dành thời gian phát triển các công cụ để phân tích và nghiên cứu dữ liệu nhập của mình. Tránh lối mòn trong suy nghĩ về dữ liệu như là một đầu vào.
Tất cả dữ liệu có các tính năng ẩn chứa sức mạnh dự đoán to lớn nếu bạn có thể trích xuất chúng. Đôi khi bạn phải tự làm điều này, đôi khi bạn có thể phát triển mô hình deep learning theo cách mà nó có thể làm được điều này một mình. Hãy suy nghĩ về dữ liệu của bạn như là một đầu vào cho một thuật toán mật mã – nhưng thay vì mã hóa một văn bản hoặc email, nó là mã hóa cách thế giới hoạt động. Mỗi điểm dữ liệu là một đầu mối để hiểu rõ hơn.
Phân loại văn bản trong NLP là một ví dụ hoàn hảo. Bạn được cung cấp hàng trăm hoặc hàng ngàn từ, và mỗi văn bản có một class hoặc nhiều class. Có lẽ class này là tích cực, tiêu cực, hoặc trung lập, và có lẽ bạn có hàng trăm class phức tạp. Dù bằng cách nào, văn bản sẽ là code mà chúng tôi sử dụng để xác định kết quả đầu ra.
Khi bạn thật sự suy nghĩ về dữ liệu và hiểu được giá trị của chúng thì kết quả đạt được sẽ rất phi thường. Bởi suy cho cùng deep learning là dựa trên mức độ hiểu biết của chúng ta về dữ liệu.
Dành thời gian với các chuyên gia về Domain
Điều này có liên quan đến phần trước và thậm chí còn quan trọng hơn – dành thời gian để nói chuyện với những người có kiến thức về tên miền. Thảo luận kết quả của bạn với họ, thảo luận về dữ liệu với họ. Thu hút sự chú ý của họ trong quá trình thiết kế.
Bạn sẽ bị sốc khi biết việc này sẽ có ích tới dường nào. Bởi những insight cũng như ý kiến từ họ luôn có độ chính xác cao đến kinh ngạc. Nếu bạn không có chuyên gia về miền, hãy dành thời gian để tự học. Tránh cố gắng xây dựng một mô hình deep learning cho một vấn đề bạn không hiểu.
Loại bỏ ý tưởng rằng deep learning giống như việc đi qua một mê cung dựa vào linh tính. Trong thực tế, bạn có thể đặt được sự “hoàn hảo” trong deep learning bằng cách làm theo đúng phương pháp và cố gắng giải quyết những vấn đề chính xác. Hãy luôn tự hỏi bản thân vì sao lại như vậy?
Mặc dù phương pháp tôi mô tả có thể trái ngược với ý tưởng thiết kế dựa trên số liệu, nhưng tôi thấy nó lại thật sự rất hiệu quả khi bạn bắt tay vào làm. Đôi khi chỉ có thực hành mới đem lại cho ta sự hiểu biết tường tận hơn là chỉ nhìn vào số liệu.
Học như trẻ nhỏ
Khi tôi kiểm tra một thay đổi trong thiết kế, tôi cố gắng tìm ra lý do tại sao nó hoạt động. Phương pháp này cho phép tôi tiếp tục nâng cao hiểu biết của mình. Tôi có thể không phải là một chuyên gia, nhưng với thời gian, mọi chuyện điều có thể miễn bạn luôn cố gắng bám theo nó.
Tôi tiếp tục hỏi lý do tại sao cho đến khi cảm thấy đã thực sự hiểu tường tận cho quyết định đó. Thường thì một câu hỏi luôn dẫn đến câu hỏi khác, và vài ngày sau bạn có một sự hiểu biết mới và sâu sắc về một loạt các khái niệm. Sau đây là một ví dụ khá điển hình cho trường hợp trên:
- Tại sao nên sử dụng một LSTM để mã hóa các câu của tôi?
- Làm thế nào để một LSTM hoạt động?
- Cách tốt nhất để regularize một LSTM là gì?
- Tôi nên decode các trình tự từ đầu ra LSTM như thế nào?
- Liệu một GRU có thể hoạt động tốt hơn hay nhanh hơn LSTM? Tại sao?
- Tôi nên khởi tạo các layer LSTM theo cách nào? Tại sao?
- LSTM này chậm, liệu tôi có thể tăng tốc độ nó lên không?
- Tại sao một LSTM truyền thống lại hoạt động chậm hơn nhiều so với một layer LSTM tối ưu hóa Cuda trên GPU?
Tôi gọi chúng là những lỗ thỏ vì con đường học tập là ngẫu nhiên và không chắc chắn ngay từ đầu. Đã từng tôi chỉ để cho bản thân mình khám phá những câu hỏi tôi có. Thật ra tôi không lo lắng rằng nó là lộn xộn. Phương pháp này là cách tôi đã học được mọi thứ từ trước tới nay trongcuộc đời của mình, và nó luôn luôn đưa tôi đến đúng nơi. Tuy vậy, cách tiếp cận này có nhược điểm là mất nhiều thời gian, nhưng phần lớn các nhà khoa học dữ liệu sẽ không hề ngại vấn đề này.
Hỏi đúng câu hỏi
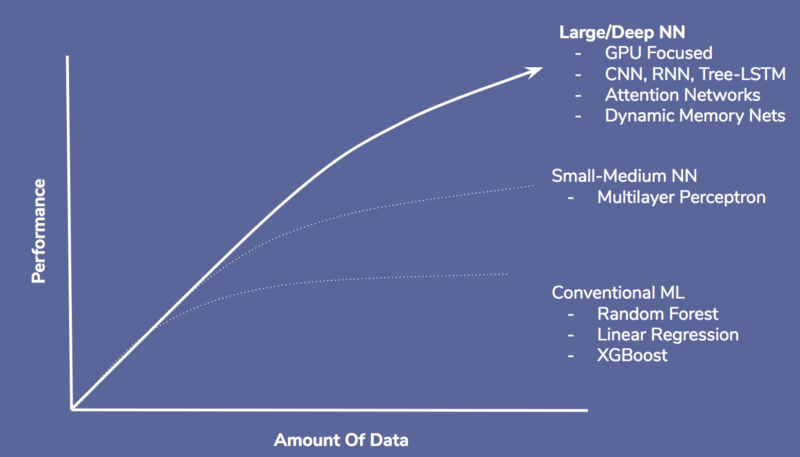
Xác định đúng vấn đề trong deep learning là điều thiết yếu. Deep learning rất giỏi về ngôn ngữ, phân loại hình ảnh, dịch lời nói, thông dịch cho máy và game (cờ tướng, Starcraft). Nó kém hiệu quả hơn ở các lĩnh vực machine learning truyền thống như phát hiện gian lận trong thẻ tín dụng, định giá tài sản và chấm điểm tín dụng.
Có lẽ trong tương lai, chúng ta sẽ có các mô hình hoàn hảo hơn, với những phương pháp tối ưu hóa để làm cho deep learning được áp dụng rộng rãi hơn nhưng hiện tại nó vẫn còn rất giới hạn.
Lý do mà deep learning có khả năng thực hiện những task phức tạp là nhờ vào các mô hình. Với tất cả các bước trong phân tích và liên kết dữ liệu. Một mạng thần kinh nhân tạo sẽ tìm ra và khai thác những dữ liệu này theo cách mà không con người nào có thể làm được.
Hơn nữa, trong khi machine learning truyền thống cũng có thể được áp dụng cho các lĩnh vực này, chúng lại rất hạn chế và không có hiệu quả cao. Đó là lí do vì sao network của machine learning không có được khả năng phân tích tốt với số lượng dữ liệu lớn như deep learning.
Hoang tưởng đôi khi cũng là cần thiết
Chủ đề cuối cùng và có lẽ là quan trọng nhất – Làm thế nào để đảm bảo mô hình của bạn hoạt động tốt? Thật không may bởi không có một giải pháp duy nhất nhưng có những tiêu chí mà bạn có thể dựa vào đó để đánh giá.
Khi thiết kế một mạng lưới, tôi thường nghĩ là nó không hoạt động chính xác. Tôi liên tục tự hỏi liệu các điểm số có đang đánh lừa mình, hoặc có những lỗi hiếm gặp mà tôi không lường trước được. Kết quả là, tôi xây dựng các công cụ xem xét và kiểm tra theo nhiều cách.
Vấn đề là phải nhận ra rằng mô hình của bạn sẽ rất phức tạp cũng như là ta sẽ chỉ hiểu được một phần của quá trình đưa ra quyết định. Đôi khi bạn học được một ít về mô hình của mình và cách kiểm soát chúng.
Đôi khi bạn phải chấp nhận rằng nó không phải lúc nào cũng hiệu quả. Vấn đề thường là giảm nhẹ chứ không phải là loại bỏ. Bất kỳ hệ thống deep learning nào cũng có hệ thống kiểm soát chất lượng thông minh (QA) đứng phía sau. Hệ thống kiểm soát chất lượng đó hoạt động như là hàng phòng vệ cuối.
Bằng cách sử dụng các quy trình QA thích hợp, bạn sẽ có được các số liệu cần thiết cũng như là liên tục cải tiến bản thân và mô hình của bạn. Và như vậy, tỷ lệ thành công của chúng ta sẽ tăng lên rõ rệt.
Có thể bạn quan tâm:





")