

Bài viết được sự cho phép của tác giả Kien Dang Chung
Video trong bài viết
Trong bài trước, chúng ta đã thu thập và làm sạch dữ liệu, nhưng với những con số như vậy thật khó để nhận ra những quy luật hoặc có ý tưởng để thực hiện những bước tiếp theo. Đây là lúc chúng ta cần đọc dữ liệu đã thu thập được và thực hiện phân tách những dữ liệu cần thiết cũng như trực quan hóa chúng thông qua các biểu đồ.
Tìm việc làm python lương cao các công ty lớn

Xử lý file csv với Python
File cost_revenue_clean.csv là file đã được làm sạch những thông tin nhiễu, không chính xác và cả định dạng lại để máy tính có thể hiểu được. Chúng ta cần đưa dữ liệu này vào máy tính để có thể sử dụng cho các mô hình dự đoán, như vậy các dữ liệu này có thể biểu thị bằng các biểu đồ, nó chứa đựng nhiều thông tin hơn một bảng dữ liệu chỉ toàn các con số.
Trước khi bắt đầu, bạn nên làm quen với Jupyter một công cụ không thể thiếu khi lập trình ngôn ngữ Python. Jupyter cho phép bạn thực hiện các đoạn code Python trực tuyến hoặc bạn có thể cài đặt trên máy tính cá nhân. Ở phần tiếp theo này, giả định bạn đã cài đặt hoặc biết cách sử dụng Jupyter trực tuyến tại Jupyter.org.
Đầu tiên, chúng ta tải lên các file dữ liệu cost_revenue_clean.csv với nút Upload trong trang Jupyter. Sau đó, chúng ta sẽ sử dụng module pandas để có thể đọc file dữ liệu này.
import pandasPandas là một thư viện Python mã nguồn mở với nhiệm vụ cấu trúc và phân tích dữ liệu. Để đọc dữ liệu từ file csv chúng ta sử dụng phương thức read_csv().
data = pandas.read_csv('cost_revenue_clean.csv')Trong Jupyter khi code xong, để thực thi bạn nhấn tổ hợp phím Shift + Enter hoặc bấm vào nút Run trong thanh menu nhanh.
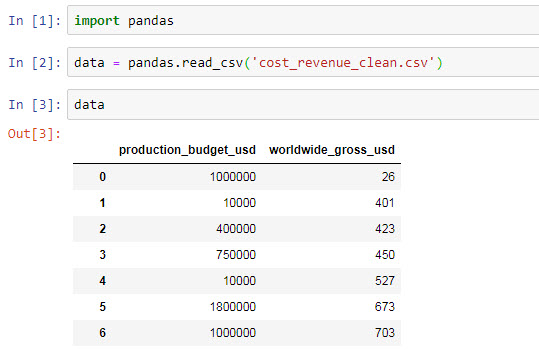
Dữ liệu của chúng ta khoảng hơn 5000 bản ghi, do vậy để có thể nhìn dữ liệu này dưới góc nhìn khoa học, chúng ta sử dụng câu lệnh:
data.describe()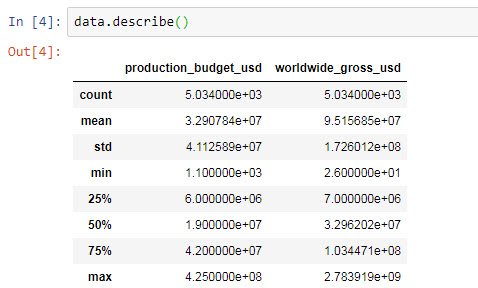
Chúng ta có các thông tin thống kê như sau:
- count: tổng số các bản ghi trong dữ liệu
- min, max: giá trị lớn nhất nhỏ nhất trong dải dữ liệu
- mean: giá trị trung bình
Chú ý, khi làm việc với các số liệu dạng khoa học, các con số sẽ có định dạng khoa học theo kiểu hàm mũ, thay thế một phần số đó với e +n. Ví dụ:
12345678901 sẽ được hiển thị là 1.23e +10
DataFrame
DataFrame là cấu trúc dữ liệu hai chiều giống kiểu dạng bảng dữ liệu, nó cho phép áp dụng các thuật toán trên các dòng và cột. DataFrame sử dụng cho rất nhiều các kiểu nhập liệu như:
- Danh sách
- Thư viện
- Series
- …
Để sử dụng DataFrame chúng ta cần import nó dưới dạng một thành phần của pandas.
from pandas import DataFrameChú ý, Jupyter hỗ trợ tự động hoàn thành (autocomplete) các từ khóa, do đó chỉ cần gõ vài ký tự trong từ khóa sau đó nhấn Tab là nó tự động chèn vào từ khóa đầy đủ giúp cho chúng ta gõ code nhanh hơn và tránh được những lỗi đánh máy như viết chữ hoa – thường.
Chúng ta thực hiện lấy ra các cột dữ liệu thông qua DataFrame được gọi là bóc tách hay phân tách dữ liệu từ dữ liệu gốc.
X = DataFrame(data, columns = ['product_budget_usd'])
y = DataFrame(data, columns = ['worldwide_gross_usd'])Bài hướng dẫn dừng lại tại đây, trong bài tiếp theo chúng ta sẽ vẽ biểu đồ dữ liệu có được khi phân tách.
Bài viết gốc được đăng tải tại allaravel.com
Có thể bạn quan tâm:
- Tài liệu làm chủ Python trong vòng 4 tuần (Phần 2)
- Biến số và kiểu dữ liệu số trong Python
- Cấu trúc dữ liệu từ điển Dictionary trong Python
Xem thêm Việc làm it đà nẵng, hcm, hà nội hấp dẫn trên TopDev



")








 trong Python")
