

Apache Spark là một công cụ đa ngôn ngữ cho phép xử lý dữ liệu, khoa học dữ liệu (data science) và học máy (machine learning) trên các node đơn (single-node machines) hoặc trên clusters.


Không chỉ đơn giản như vậy, Apache Spark còn có nhiều hơn các tính năng hay ho. Vậy anh em cùng lướt qua xem 10 tính năng nổi bật trong Apache Spark là gì?
1. Fault tolerance
Tính năng đầu tiên của Apache Spark là Fault tolerance. Fault tolerance ở đây anh em có thể hiểu là khả năng chịu lỗi, khả năng xử lý lỗi. Apache Spark ngay từ khi bắt đầu đã được thiết kế để hanler lỗi từ các worker nodes.
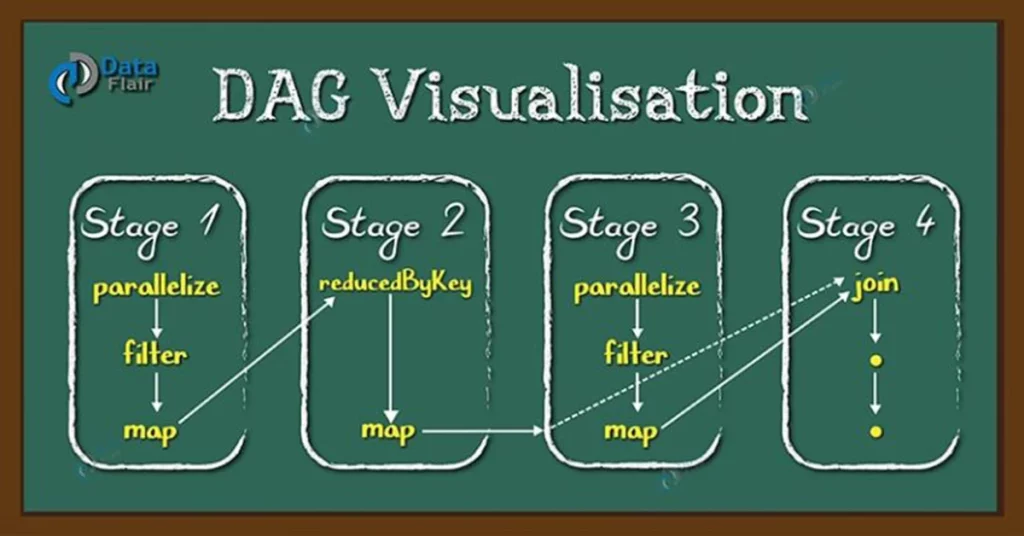
Spark đạt được khả năng này nhờ vào sử dụng DAG và RDD (Resilient Distributed Datasets). DAG ở đây chứa tất cả các bước (step) cần thiết để hoàn thành một task. Tất cả đều được ghi lại. Chính vì vậy, khi xảy ra lỗi ở nodes worker nào đó, ta có thể tái hiện lỗi từ DAG đã lưu hiện có.
2. Dynamic In Nature
Tính năng thứ hai của Apache Spark là Dynamic In Nature. Cái này anh em có thể hiểu
The applications can be written quickly in Java, Scala, Python, R. Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells. Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application. Ứng dụng có thể viết nhanh chóng với Java, Scala, Python, R. Spark cung cấp hơn 80 toán tử cao cấp cho phép xây dựng song song các ứng dụng. Ta cũng có thể sử dụng nó để tương tác từ Scala, Python và R Shells. Spark cũng cung cấp các thư viện mạnh bao gồm SQL và DataFrames, MLlib cho học máy, GraphX và Spark Streaming. Ta có thể kết hợp lại với nhau để xây dựng nhanh chóng ứng dụng của mình.

3. Lazy Evaluation
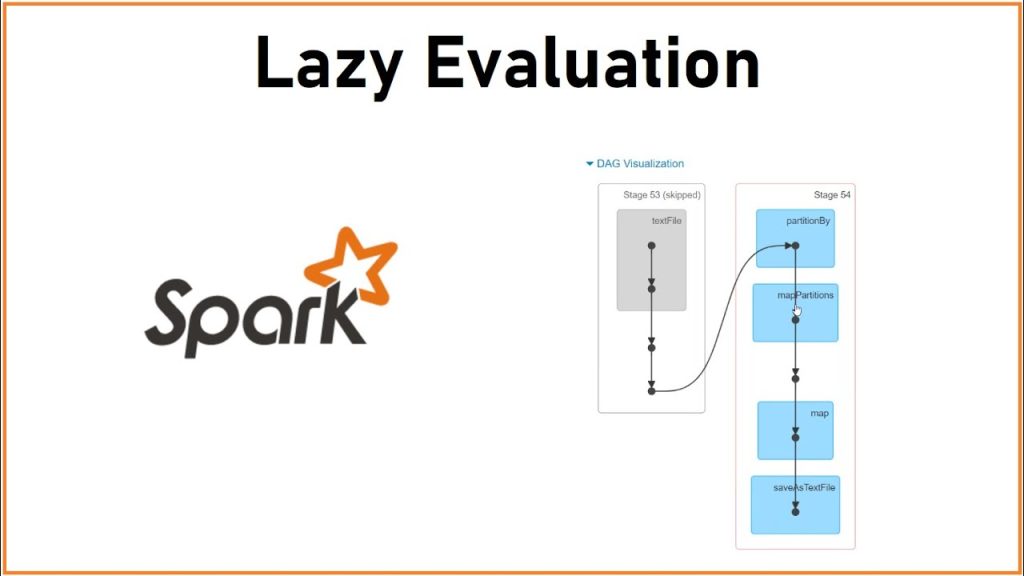
Tính năng thứ 3 của Spark là Lazy Evaluation. Với Spark thì không có bất cứ sự chuyển đổi (transformation) nào được thực hiện ngay lập tức. Tất cả đều là lazy, mỗi khi anh em thêm vào, nó sẽ đi qua DAG. Kết quả cuối cùng chỉ được đưa ra khi anh em gọi tới actions đó.
Hơn nữa, tất cả các actions liên quan tới Spark đều sẽ hiển thị lên (trực quan hoá) trước khi anh em gọi.
4. Real-Time Stream Processing
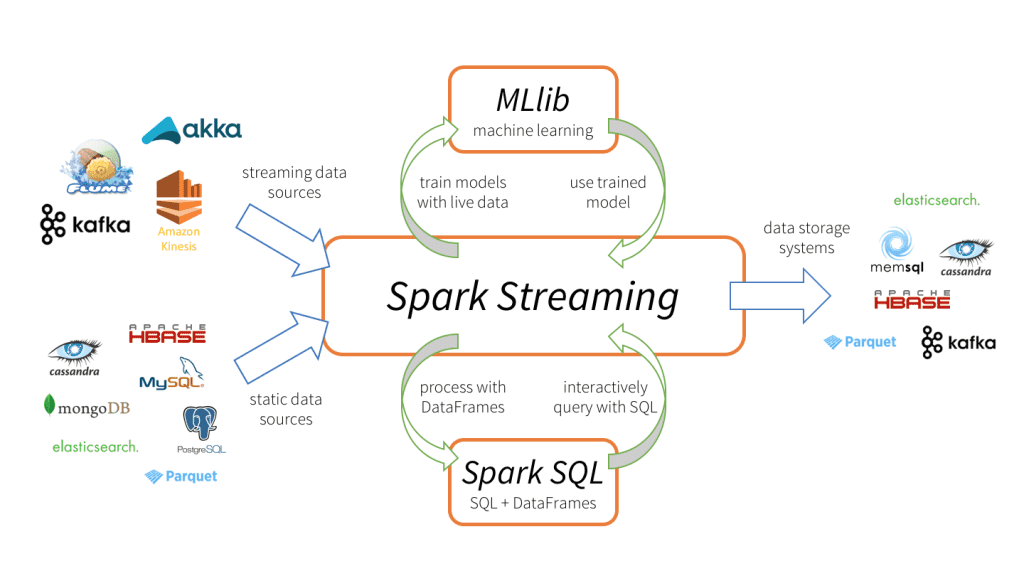
Tính năng thứ 4 của Apache Spark là Stream Processing ở chế độ Real Time. Spark Streaming đưa ra các API tích hợp ngôn ngữ của Apache Spark vào quá trình xử lý của stream. Bình thường anh em viết batch jobs theo cơ chế từ trên xuống dưới. với Apache Spark API cũng vậy, tất cả sẽ được viết như các truyền thống.
5. Speed
Spark cho phép các ứng dụng chạy trên Hadoop chạy nhanh hơn 100 lần (in memory) và nhanh gấp 10 lần (trên disk). Để tăng được tốc độ này, Spark giảm thiểu hoạt động đọc ghi ở các bước trung gian (operations for intermediate). Tất cả sẽ lưu ở trên memory và chỉ thực sự ghi ra đĩa khi cần thiết.
Một số công cụ cũng giúp Spark tăng tốc độ như DAG, query optimizer và highly optimized physical.
6. Reusability
Tính năng thứ 6 của Apache Spark cho phép tái sử dụng code. Spark code có thể sử dụng cho batch-processing. Các streaming cũng có thể kết nối với nhau (joining streaming data). Ở trạng thái streaming (streaming state), Spark cũng cho phép thực hiện các ad-hoc queries.
Xem thêm tuyển dụng Java lương cao trên TopDev
7. Advanced Analytics
Apache Spark từ đâu đã là tiêu chuẩn để xử lý các dữ liệu lớn hoặc cực lớn. Spark cung cấp các thư viện phục vụ riêng cho Machine Learning, xử lý đồ hoạ (graph processing libraries). Tất cả các thư viện này đều hoạt động trơn tru dưới sự hỗ trợ của Spark.
8. In Memory Computing
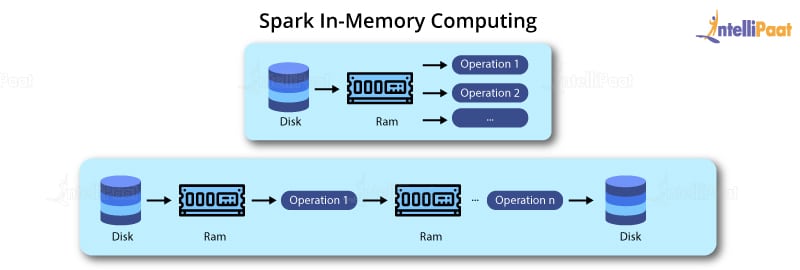
Không giống như Hadoop MapReduce, Apache Spark có khả năng xử lý các tác vụ trong bộ nhớ và không bắt buộc ghi các kết quả hoặc kết quả của các bước trung gian này vào trong bộ nhớ. Tính năng này cho phép tăng tốc độ xử lý của Apache Spark.
Kết quả của từng bước trung gian nếu cần xử lý ở bước sau cũng sẽ lưu ở trong bộ nhớ để có thể đem ra tái sử dụng.
9. Supporting Multiple languages
Apache Spark tích hợp đa ngôn ngữ. Hầu hết đều có API cho các ngôn ngữ Java, Scala, Python và R. Ngoài ra, còn có các tính năng nâng cao với ngôn ngữ R để phân tích dữ liệu. Ngoài ra Spark có bộ SQL riêng là Spark SQL, tương tự với SQL. Cho phép anh em làm quen nhanh để phát triển.

10. Integrated with Hadoop
Apache Spark tích hợp tốt với HDFS file system trên Hadoop. Cung cấp nhiều định dạng như Json, csv, orc, avro.

11. Tham khảo thêm về Apache Spark
Cảm ơn anh em đã đọc bài – Thank you for your time – Happy coding!
Tác giả: Kiên Nguyễn
Có thể bạn quan tâm:
- WebAssembly – Tương lai của các ứng dụng Web
- Các nhóm ngành công nghệ thông tin, liệu có phù hợp với bạn?
- DRM là gì? DRM hoạt động như thế nào?
Tìm kiếm việc làm IT mới nhất tại TopDev!


 là gì? Đặc điểm và ứng dụng của Big Data")