

Cũng gần 9 tháng kể từ bài 1 ra mắt, trong bài này mình sẽ chia sẻ cách hệ thống Teamcrop đã tối ưu thế nào để tăng tốc cho hệ thống Microservices của mình. Cũng như bài 1 có đề cập, dữ liệu trong hệ thống microservices khá phân tán và khi cần lấy dữ liệu nếu không thiết kế tốt thì sẽ tốn rất nhiều thời gian cho các request lấy dữ liệu. Ví dụ lấy danh sách đơn hàng là một ví dụ rõ ràng nhất có nêu ở bài trước.
Teamcrop cũng lưu dữ liệu dạng này, trong một đơn hàng được lưu trong database thì chỉ lưu ID (Khóa ngoại) của các bảng như nhân viên, cửa hàng, nguồn đơn hàng…mà các thông tin này chỉ được cung cấp bởi các service liên quan như service Nhân viên, Store và Metadata. Để hiển thị thông tin như giao diện thì cần phải gọi thêm nhiều request (Restful) để fetch data từ các nguồn này và đây là cách hoàn toàn không hiệu quả bởi ảnh hưởng đến thời gian chờ của người dùng.
Trong kiến trúc của Teamcrop, các thông tin như nhân viên, cửa hàng, nhà kho, sản phẩm, … này được gọi là Tài nguyên công ty (Company Resource– CR) và hiện Teamcrop có khoảng gần 20 company resource.

Cách hoạt động của các Company Resource:
Các company resource cũng là dữ liệu và tất nhiên vẫn có các API như các resource khác, hầu hết đều được quản lý (CRUD) và có giao diện tương ứng để quản lý. Chỉ có một khác biệt là các company resource sẽ có thêm 1 web service cho phép lấy toàn bộ dữ liệu, gọi là api /fulldata. API này cho phép lấy toàn bộ dữ liệu resource, không phân trang.
Khi có một user truy cập vào website thì sẽ load toàn bộ các company resource và lưu trữ trong trình duyệt. Mình có thể setup thêm giao diện để thể hiện progress bar, khi nào toàn bộ company resource được load hết thì cơ chế router của web sẽ bắt đầu và tiến hành load giao diện tính năng đang truy cập. Hình dưới là ví dụ một action viết bằng PHP của việc lấy một company resource là Vendor (thương hiệu):
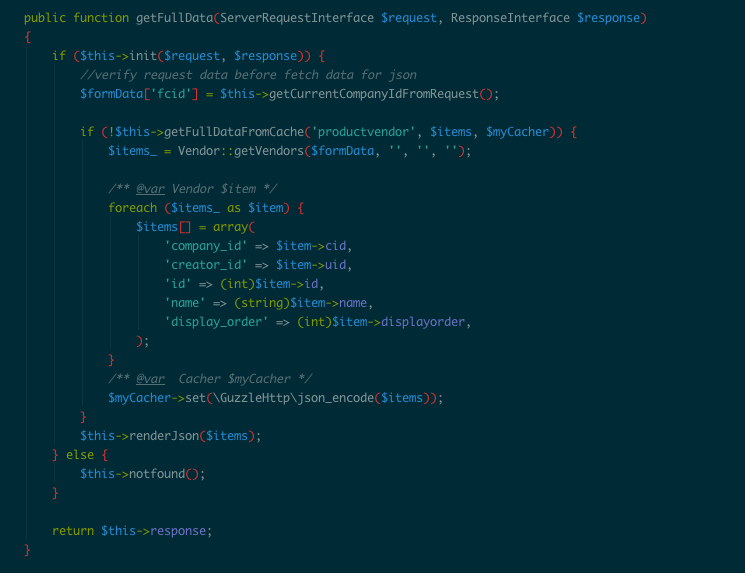
Company Resource sẽ ảnh hưởng thời gian tải trang
Nếu đọc đến đây thì sẽ có nhiều bạn thắc mắc là nếu mỗi truy cập đều phải load toàn bộ Company Resource thì sẽ chờ khá lâu bởi vì mỗi CR sẽ cần 1 request đến /fulldata và API này cũng phải lấy toàn bộ data của resource và response về.
Đối với phía server thì sẽ không có vấn đề nhiều vì mình sẽ tận dụng cache (Redis) để lưu kết quả vào memory và khi có request thì mình sẽ lấy từ cache ra mà thôi.
Ở phía client (trình duyệt) thì mới là vấn đề lớn, bởi dù server có nhanh thì có bao nhiêu company resource thì cũng sẽ tốn ngần ấy số request lên server để lấy /fulldata. Tuy nhiên, Teamcrop hầu như không tốn 1 request nào cho các company resource khi sử dụng…Service Worker của trình duyệt.
Đối với các API /fulldata thì script trong service worker của mình sẽ lấy từ cache trên trình duyệt ra mà không phải tốn 1 request nào lên server. Như vậy là tiết kiệm được mấy chục request và có được một số lượng data để hỗ trợ lấy dữ liệu.
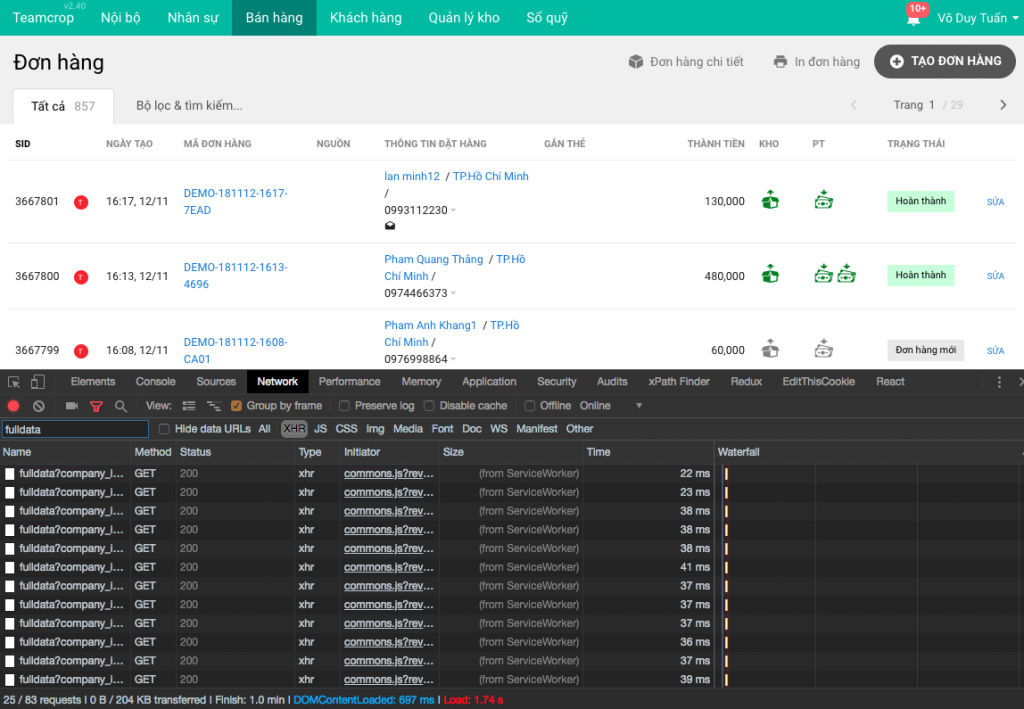
Company Resource sẽ được lưu trữ thế nào?
Sau khi lấy được các dữ liệu company resource thì việc lưu trữ và sử dụng các dữ liệu này cũng là một vấn đề lớn. Bởi các company resource này sẽ được dùng cho việc tìm kiếm theo 1 ID (getById), tìm theo một số tiêu chí (search) và lấy toàn bộ danh sách (getList).
Để đảm bảo quá trình truy xuất, tìm kiếm thì nó phải nhanh cũng như gần gũi, dễ sử dụng nên mình đã chọn TaffyDB, được coi là một thư viện nhỏ gọn, In-memory Database, hỗ trợ tìm kiếm theo ID, điều kiện..và khá dễ dùng. Mỗi Company Resource sau khi lấy về sẽ trở thành 1 database và có thể truy xuất data thoải mái. Khá nhanh bởi vì nó là in-memory.
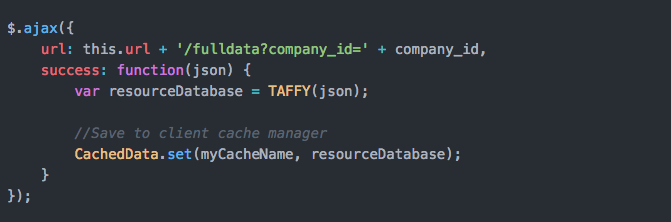
Như vậy thì từ giờ, mỗi khi có 1 dữ liệu có ID là ID của một company resource thì có thể tìm kiếm và lấy thông tin một cách nhanh nhất từ bộ nhớ của trình duyệt mà không phải tốn công JOIN bảng, request giữa các service hoặc client gửi request để lấy detail.
Tuy nhiên, một vấn đề lớn hơn đã xuất hiện đó là nếu dữ liệu company resource đã cache hoàn toàn ở trình duyệt thì khi có dữ liệu mới thì làm sao cập nhật (hay xóa cache). Đối với vấn đề này phát sinh 2 tình huống từ dễ đến khó, tình huống đầu tiên là xóa cache đối với người refresh lại trang web (reload) và tình huống thứ 2, đau đầu hơn là bởi vì Teamcrop là dạng Single Page App (SPA), nếu người dùng không reload trang thì làm sao cập nhật dữ liệu mới nhất. Mình sẽ xử lý lần lượt từng tình huống.
Xóa cache của Company Resource khi reload trang
Đối với trường hợp người dùng reload lại trang web thì chỉ cần thêm cơ chế versioning vào các company resource là giải quyết được.
Những thao tác thay đổi dữ liệu liên quan đến Company Resource (thêm, xóa, sửa) thì đều được gọi 1 API để nâng version của resource tương ứng.

Trước khi request các /fulldata API, hệ thống sẽ gửi request lấy thông tin version của các company resource, từ đó mới request để lấy full data. Do version được nối vào URL của fulldata nên Service Worker sẽ kích hoạt cơ chế cache theo URL, nếu version không đổi thì sẽ không request lên server, ngược lại thì sẽ request lên server.
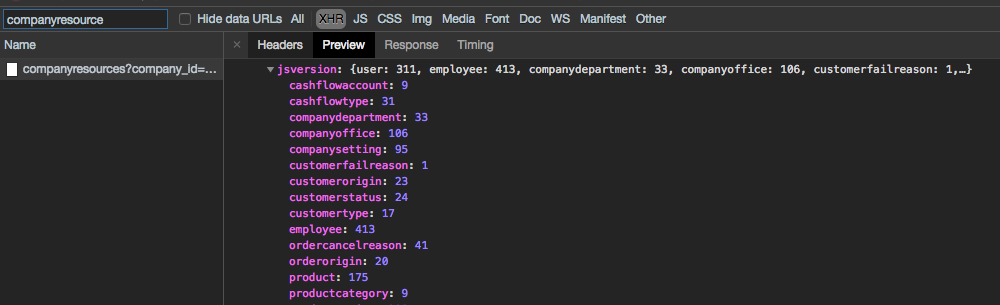
Thậm chí còn làm tính năng nho nhỏ trên giao diện để debug version của các resource trong trường hợp không thể inspect được.
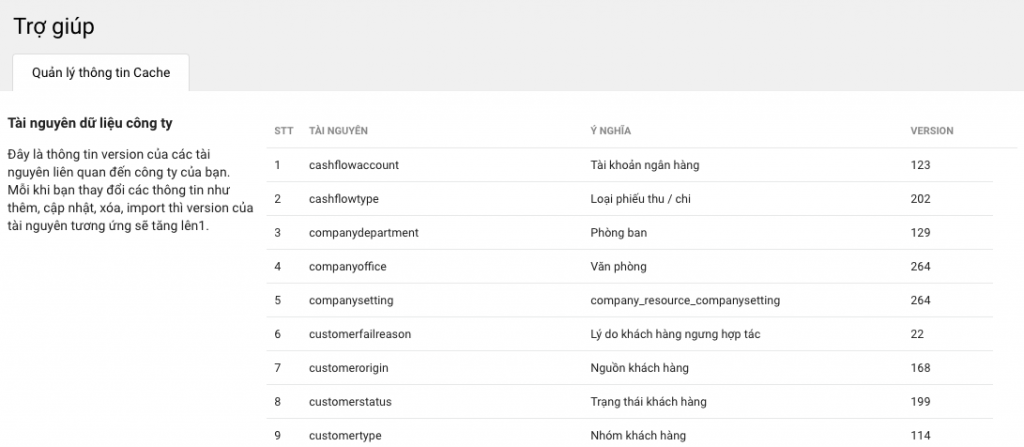
Xóa cache của Company Resource khi đang sử dụng và không reload
Đối với trường hợp một user vẫn “miệt mài” làm việc và không reload trang, bởi đặc thù của Single Page App là không reload mỗi khi chuyển tính năng nên xóa cache của company resource cho đối tượng này sẽ không theo cách thông thường. Bài toán đặt ra là làm sao trigger (thông báo) cho trình duyệt biết là có sự thay đổi là được bởi vì nếu được trigger thì chỉ cần gọi ajax lên Company Resource API sẽ lấy được bảng version của các resource và đối chiếu cái nào tăng thì lấy bản mới của /fulldata.
Suy nghĩ một hồi và nghĩ ngay đến giải pháp sử dụng Socket. Và Teamcrop sử dụng Pusher để cung cấp giải pháp socket bởi vì đây là một trong những dịch vụ tốt nhất hiện nay đối với dịch vụ socket.
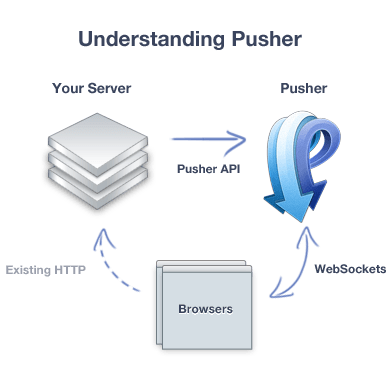
Nhằm tận dụng cơ chế web socket sẵn có của Teamcrop (dùng cho cơ chế web notification) nên trình duyệt tiến hành “subscribe” để nghe trên một channel và mỗi khi version tăng thì server (PHP) của Teamcrop gửi một message cho trình duyệt đang lắng nghe ở một channel chung của công ty, tất nhiên thông qua Pusher API.
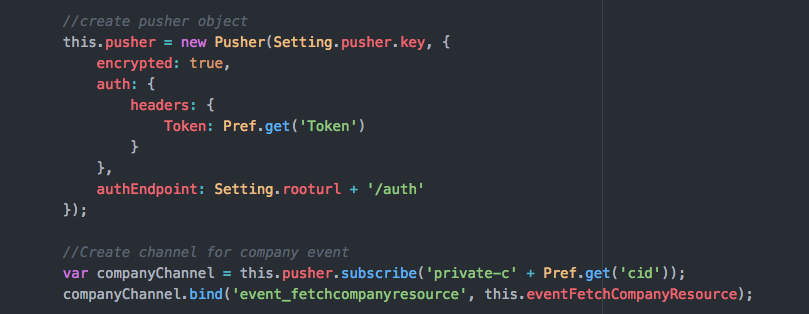
Sample code ở client (Javascript):
Sample code ở server (PHP):
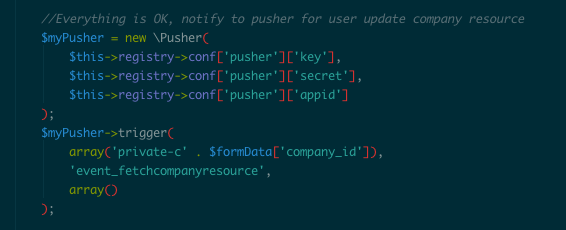
Như vậy, mỗi khi company resource service nhận được yêu cầu nâng version thì sẽ trigger và client sẽ tự động cập nhật dữ liệu đang cache trên trình duyệt. Và giải quyết ổn thỏa bài toán cache data cho Company Resource.
Tiêu chí nào để trở thành Company Resource?
Như từ đầu đã chia sẻ, Company Resource sẽ lưu ở máy giúp việc “phân giải” các ID khóa ngoại thành dữ liệu để hiển thị nhằm cải tiến performance chung của toàn hệ thống. Tuy nhiên, không phải tất cả tài nguyên đều có thể trở thành Company Resource.
Trước tiên, cần xác định rõ là Company Resource không phải là Transaction Data, ví dụ Đơn hàng, Khách hàng…không thể nào là ứng cử viên trở thành Company Resource bởi tính thay đổi cũng như số lượng của nó. Chỉ nên chọn những dữ liệu thường xuyên được tham chiếu, số lượng dữ liệu ít, tránh làm trình duyệt lưu quá nhiều dữ liệu vào bộ nhớ.
—
Lời kết, như vậy cùng với việc thay đổi mô hình microservice thì cũng phát sinh nhiều vấn đề mới liên quan đến kiến trúc này. Trên đây chỉ là một giải pháp cho một bài toán cụ thể mà Teamcrop gặp phải trong quá trình vận hành hệ thống của mình. Kỳ tiếp theo (kỳ 3) mình sẽ đề cập đến một bài toán cụ thể hơn là Export dữ liệu ra file (vd Excel). Bởi vì đặc thù là dữ liệu phân tán, nên export dữ liệu trong hệ thống cũng là một bài toán khá thú vị.
Có thể bạn quan tâm:
Xem thêm việc làm Microsoft tại TopDev
Nguồn: Bloghoctap.com













