

Bài viết được sự cho phép của tác giả Edward Thien Hoang
Tôi đã có một bài viết về Domain Drive Development (DDD) – First thought để “đặt vấn đề” cho DDD, các bạn có thể tham khảo ở đó trước. Trong phạm vi bài viết này, tôi sẽ tham khảo và diễn đạt lại từ bài viết Domain-Drive Design của tác giả herbertograca.
Domain-Drive Design do Eric Evans tạo ra trong cuốn sách nổi tiếng của ông về Domain-Driven Design: Tackling Complexity in the Heart of Software, xuất bản năm 2003. Cuốn sách của Eric Evans là chìa khóa chính thức hóa nhiều khái niệm phát triển phần mềm hiện nay.

Tôi không thể đưa ra một đánh giá toàn diện về DDD trong một bài viết trên blog. Có quá nhiều khái niệm quan trọng liên quan đến DDD. May mắn thay, đó cũng không phải là mục tiêu ở đây. Tuy nhiên, những gì tôi sẽ làm là liệt kê các khái niệm DDD mà tôi thấy có liên quan đến cách tôi muốn tổ chức mã và cách tôi nghĩ về Kiến trúc: các khái niệm hệ thống rộng tạo thành nền tảng cho phát triển tính năng.
Trong bài viết, tôi sẽ nói về:
- Ubiquitous language (Ngôn ngữ chung)
- Layers Bounded contexts
- Anti-Corruption Layer
- Shared Kernel
- Generic Subdomain
UBIQUITOUS LANGUAGE
Một vấn đề thường xảy ra trong phát triển phần mềm, xoay quanh sự hiểu biết về mã nguồn, nó là gì, nó làm gì, nó như thế nào, tại sao nó lại … nó thậm chí còn phức tạp hơn để hiểu mã nguồn khi nó sử dụng một thuật ngữ khác với thuật ngữ mà các chuyên gia về nghiệp vụ (domain expert) sử dụng. Ví dụ, nghiệp vụ chuyển tiền trong ngân hàng được các chuyên gia gọi là remittance, tuy nhiên khi các developer nghe được từ “chuyển tiền”, họ lại để trong code là money transfer, điều này có thể gây ra nhiều nhầm lẫn khi thảo luận về ứng dụng. Tuy nhiên, hầu hết sự mơ hồ này có thể được giải quyết bằng cách đặt tên đúng các lớp và các phương thức, làm cho chúng thể hiện một đối tượng và phương pháp nào đó trong ngữ cảnh của nghiệp vụ.
Ý tưởng chính của việc sử dụng một Ngôn ngữ chung (Ubiquitous language) là để giúp cho việc không nhầm lẫn mơ hồ giữa các khái niệm về nghiệp vụ với cách đặt tên, ánh xạ các khái niệm đó ở trong mã nguồn. Code, class, method, properties và đặt tên mô-đun phải phù hợp với ngôn ngữ chung. Nếu cần thì ta có thể refactor (tái cấu trúc) lại mã nguồn để đạt được điều đó, với mục đích chung là thống nhất các thuật ngữ giữa code và nghiệp vụ.
LAYERS
Tôi đã nói về Layers trong một bài viết trước, nhưng tôi sẽ viết lại trong bài viết này từ góc nhìn của DDD:
USER INTERFACE
Chịu trách nhiệm render màn hình người dùng sử dụng để tương tác với ứng dụng và dịch các đầu vào của người dùng vào các lệnh ứng dụng. Điều quan trọng cần lưu ý là “người dùng” có thể là con người nhưng cũng có thể là các ứng dụng khác kết nối với API của chúng ta, tương ứng hoàn toàn với các đối tượng Boundary trong kiến trúc EBI;
APPLICATION LAYER
Dàn xếp các đối tượng domain để thực hiện các tác vụ theo yêu cầu của người dùng hay còn gọi là các use-case. Nó không chứa business logic. Điều này giống với Interactors trong kiến trúc EBI, ngoại trừ Interactors là bất kỳ đối tượng nào không liên quan đến User Interfaces hoặc Entity, và trong trường hợp này, Application Layer chỉ chứa các đối tượng có liên quan đến một use-case. Lớp này là nơi mà Application Services thuộc về, vì chúng là nơi tổng hợp, sử dụng tất cả các loại object khác như repositories, Domain Services, Entities, Value Objects hoặc bất kỳ đối tượng Domain nào để đáp ứng yêu cầu của các use-case.
DOMAIN LAYER
Đây là lớp có chứa tất cả logic nghiệp vụ, Domain Services, Entities, Events và bất kỳ loại đối tượng khác có chứa Logic nghiệp vụ. Rõ ràng nó chính là Entity Object của EBI. Đây là trung tâm, là trái tim của hệ thống. Domain Services sẽ chứa các logic nghiệp vụ không phù hợp với một Entity, thường là kết hợp một số Entity trong việc thực hiện một số công việc liên quan đến nghiệp vụ;
INFRASTRUCTURE
Các khả năng kỹ thuật hỗ trợ các Layers ở trên, ví dụ như persistence hoặc messaging.
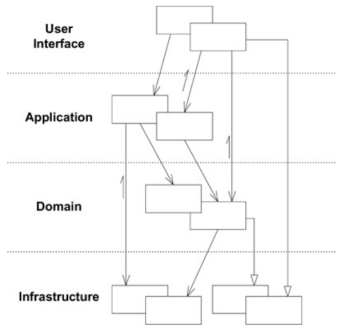
Eric Evans, 2003
BOUNDED CONTEXTS
Trong một ứng dụng doanh nghiệp, có thể có rất nhiều model, các khái niệm cũng như số lượng và kích thước của team làm việc trên codebase là rất lớn. Điều này mang lại cho chúng ta hai vấn đề:
- Các developer làm việc trên codebase càng lớn thì càng khó nhận thức và hiểu đúng về những gì những đoạn mã đang làm, và do đó có thể tạo ra bug, gây khó khăn trong việc debug, hiểu đúng và ra quyết định được làm theo thế nào.
- Các nhiều developer làm việc trên cùng một codebase, càng khó khăn hơn để hợp tác và có một tầm nhìn chung về kỹ thuật và nghiệp vụ của ứng dụng.
Nói cách khác, đó là 2 vấn đề lớn cần giải quyết khi làm việc với các ứng dụng tầm cỡ enterprise.
Giải pháp thông thường cho một vấn đề lớn là chia nhỏ nó thành những phần nhỏ hơn, hay còn gọi là “bounded contexts”. Nơi mỗi phần phục cho những đối tượng người dùng khác nhau. Nói cách khác, trong 1 hệ thống phần mềm doanh nghiệp, nơi mà hệ thống sẽ phục vụ cho rất nhiều đối tượng người sử dụng khác nhau, việc chúng ta nên làm là chia nhỏ hệ thống đó ra thành những hệ thống nhỏ hơn, đơn lẻ về nhiệm vụ, và đối tượng người dùng. Ví dụ hệ thống nhân sự, kế toán, tiền lương. Mỗi hệ thống có 1 ngữ cảnh riêng gọi là “bounded contexts”, nơi mà nó hệ thống con đó chỉ có hiểu biết về ngữ cảnh, nghiệp vụ nó đảm nhiệm.
Two subsystems commonly serve very different user communities.
Eric Evans 2014, Domain-Driven Design Reference
Các bounded contexts xác định một ngữ cảnh áp dụng một phần riêng biệt của mô hình nghiệp vụ. Việc cô lập này có thể đạt được bằng cách tách các logic kỹ thuật, tách biệt codebase, tách biệt giản đồ cơ sở dữ liệu (database schema) và về tổ chức team. Mức độ cô lập bounded context, như thường lệ, phụ thuộc vào tình hình thực tế: nhu cầu và khả năng chúng ta có.
Một điểm thú vị, đây không phải là một khái niệm hoàn toàn mới. Ivar Jacobson đã viết về các hệ thống con (subsystems) trong cuốn sách của mình (Object-Oriented Software Engineering: A Use Case Driven Approach), trở lại vào năm 1992, mười một năm trước Eric Evans!

Ivar Jacobson, 1992
Khi đó, ông đã có một vài ý tưởng rất cụ thể về chủ đề này:
- Hệ thống do vậy bao gồm một số các hệ thống con có thể chứa các hệ thống con của chính nó. Ở dưới cùng của phân cấp như vậy là các đối tượng phân tích (analysis objects). Các hệ thống con là một cách để cấu trúc hệ thống cho việc phát triển và bảo trì.
- Nhiệm vụ của các hệ thống con là đóng gói các đối tượng sao để làm giảm đi sự phức tạp.
Tất cả các đối tượng đảm nhiệm các phần cụ thể của chức năng sẽ được đặt trong cùng một hệ thống con - Mục đích là để có một gắn kết chức năng mạnh mẽ trong một subsystem và một sự liên kết lỏng lẽo giữa các subsystem (ngày nay được gọi là low coupling and high cohesion)
- [Một hệ thống con] nên tốt hơn nên được sử dụng bởi chỉ một actor, vì thay đổi thường được gây ra bởi một actor.
- […] bắt đầu bằng cách đặt các đối tượng điều khiển trong một subsystem, và sau đó đặt các đối tượng thực thể liên kết chặt chẽ (strongly coupled) và các đối tượng giao diện (interface objects) trong cùng một subsystem.
- Tất cả các đối tượng có gắn kết chức năng mạnh mẽ (strong mutual functional coupling) sẽ được đặt trong cùng một subsystem […]
- Liệu những thay đổi trong một đối tượng dẫn đến những thay đổi trong đối tượng kia? (Điều này bây giờ được gọi là Nguyên tắc The Common Closure Principle – Classes được xuất bản bởi Robert C. Martin trong bài báo “Granularity” năm 1996, 4 năm sau cuốn sách Ivar Jacobson)
- Liệu chúng có giao tiếp với cùng một actor?
- Có phải cả hai đều phụ thuộc vào một đối tượng thứ ba, chẳng hạn như một interface object hay một entity? Liệu một đối tượng thực hiện một số hoạt động trên đối tượng kia? (Điều này được gọi là Nguyên tắc The Common Reuse Principle – Classes, được sử dụng cùng nhau được đóng gói cùng nhau của Robert C. Martin trong bài báo “Granularity” năm 1996, 4 năm sau cuốn sách Ivar Jacobson)
- Một tiêu chí khác cho việc phân chia là phải có ít thông tin trao đổi giữa các hệ thống con khác nhau càng tốt (low coupling)
- Đối với các dự án lớn, có thể có các tiêu chí khác cho phân hệ thống con, ví dụ:
- Các nhóm phát triển khác nhau có năng lực hoặc nguồn lực khác nhau và có thể phân phối các công việc phát triển phù hợp (các nhóm cũng có thể được tách biệt về mặt địa lý)
- Trong một môi trường phân tán, một hệ thống phụ có thể được yêu cầu ở mỗi logical node (SOA, web services và micro services) Nếu một sản phẩm hiện có có thể được sử dụng trong hệ thống này, điều này có thể được coi là một subsystem (các libraries mà hệ thống phụ thuộc vào, ví dụ như ORM).
ANTI-CORRUPTION LAYER
Một Anti-Corruption Layer cơ bản là một middleware giữa hai hệ thống con. Nó được sử dụng để cô lập hai hệ thống con, làm cho chúng phụ thuộc vào layer này thay vì phụ thuộc trực tiếp vào nhau. Bằng cách này, nếu chúng ta tái cấu trúc hoặc thay thế hoàn toàn một trong các hệ thống con thì chúng ta sẽ chỉ phải cập nhật layer này để các hệ thống con khác không bị ảnh hưởng.
Điều này đặc biệt hữu ích khi có một hệ thống mới mà chúng ta cần phải tích hợp với một hệ thống có sẵn. Để không để những hệ thống cũ chịu sự ảnh hưởng từ việc thêm mới các hệ thống con mới, chúng ta tạo ra một Anti-Corruption Layer sẽ điều chỉnh API của hệ thống cũ cho các nhu cầu của hệ thống con mới.
Có 3 mối quan tâm chính:
- Điều chỉnh các API hệ thống con với những gì các client subsystems cần;
- Translate data và commands giữa các hệ thống con;
- Thiết lập trao đổi (communication) theo một hoặc nhiều hướng, nếu cần
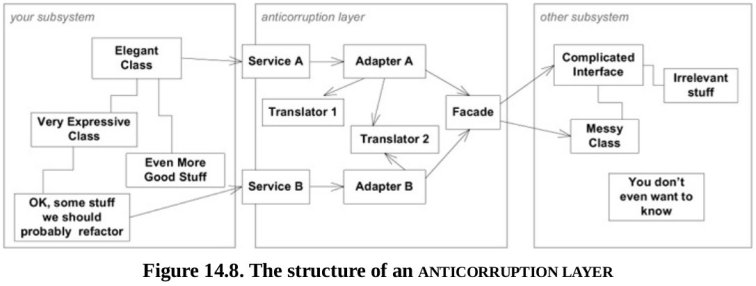
Eric Evans, 2003
Đây là một kỹ thuật được sử dụng hợp lý khi chúng ta không kiểm soát một hoặc tất cả các hệ thống con, nhưng cũng có thể sử dụng nó khi chúng ta kiểm soát tất cả các hệ thống con liên quan, ngay cả khi chúng được thiết kế tốt nhưng đơn giản có các model rất khác nhau và chúng ta muốn ngăn chặn sự rò rỉ từ model này sang model khác (thay đổi một hệ thống con để phù hợp với nhu cầu của một hệ thống con khác).
SHARED KERNEL
Trong một số trường hợp, bất chấp mong muốn của chúng ta để có các thành phần tách biệt hoàn toàn và tách rời, vẫn có một số trường hợp buộc ta phải tách một số domain code ra để chia sẻ cho nhiều component khác sử dụng.
Điều này sẽ cho phép các component vẫn giữ được tính phân tách và độc lập với các component khác mặc dù sử dụng chung những mã chia sẻ cùng (shared code), ta gọi các mã chia sẻ này với cái tên “shared kernel”.
Trường hợp ví dụ, với các events được kích hoạt bởi một component và lắng nghe bởi một hoặc một số component khác. Và tương tự cho các service interfaces and thậm chí là các entities.
Tuy nhiên, nên giữ phần Shared Kernel này càng nhỏ càng tốt, và cẩn thận khi thay đổi nó vì chúng ta có thể một cách vô tình gây ảnh hưởng đến những chỗ khác đang sử dụng nó. Điều quan trọng là mã trong Shared Kernel sẽ không nên bị thay đổi nếu không có sự tham gia và hiểu biết của tất cả các nhóm phát triển khác sử dụng nó.
GENERIC SUBDOMAIN
Một Subdomain là một phần rất biệt lập của domain. Generic Subdomain là một Subdomain không liên quan đến ứng dụng của chúng ta mà có thể được sử dụng trong bất kỳ ứng dụng nào tương tự.
Vì vậy, nếu có một ứng dụng có một phần của nó là về finance, có lẽ chúng ta có thể sử dụng một thư viện finance hiện có trong ứng dụng. Nhưng dù sao đi nữa, ngay cả khi không thể sử dụng thư viện hiện có và cần xây dựng riêng của chúng ta, nếu nó là một Generic Subdomain thì đó không phải là hoạt động cốt lõi và nó cần phải được coi là cần thiết nhưng không quan trọng. Đây không phải là phần quan trọng nhất trong ứng dụng nên không phải là nơi các chuyên gia giỏi nhất nên tập trung và thậm chí phải rõ ràng bên ngoài mã nguồn chính, nó có thể được cài đặt với một công cụ quản lý sự phụ thuộc (dependency management tool).
KẾT LUẬN
Các khái niệm DDD tôi đã chọn để tiếp cận ở đây là, một lần nữa, chủ yếu về single responsibility, low coupling, high cohesion, isolating logic để ứng dụng của chúng ta trở nên nhất quán, dễ dàng và nhanh chóng hơn để thay đổi và thích ứng với nhu cầu của doanh nghiệp.
SOURCES
1992 – Ivar Jacobson – Object-Oriented Software Engineering: A use case driven approach
1996 – Robert C. Martin – Granularity
2003 – Eric Evans – Domain-Driven Design: Tackling Complexity in the Heart of Software
2014 – Eric Evans – Domain-Driven Design Reference
Đây là bài viết trong loạt bài viết về “Tổng quan về sự phát triển của kiến trúc phần mềm“. Đây là loạt bài viết chủ yếu giới thiệu về một số mô hình kiến trúc phần mềm hay nói đúng hơn là sự phát triển của chúng qua từng giai đoạn, qua đó giúp chúng ta có cái nhìn tổng quát, up-to-date và là roadmap để bắt đầu hành trình chinh phục (đào sâu) thế giới của những bản thiết kế với vai trò là những kỹ sư và kiến trúc sư phần mềm đam mê với nghề.
Bài viết được tham khảo từ:
Tổng hợp bởi edwardthienhoang
Bài viết gốc được đăng tải tại edwardthienhoang.wordpress.com
Có thể bạn quan tâm:
- Kiến trúc phân lớp (Layered Architecture)
- Migrate từ hệ thống monolithic sang microservice – part 2
- Software Architecture Timeline
Xem thêm Việc làm IT hấp dẫn trên TopDev

