

Machine Learning là gì?
Có 2 định nghĩa khá rõ ràng về Machine Learning như sau:
- Theo Arthur Samuel (1959): Máy học là ngành học cung cấp cho máy tính khả năng học hỏi mà không cần được lập trình một cách rõ ràng
- Theo Giáo sư Tom Mitchell – Carnegie Mellon University: Machine Learning là 1 chương trình máy tính được nói là học hỏi từ kinh nghiệm E từ các tác vụ T và với độ đo hiệu suất P. Nếu hiệu suất của nó áp dụng trên tác vụ T và được đo lường bởi độ đo P tăng từ kinh nghiệm E
Ví dụ cho định nghĩa của Tom Mitchell
- Ví dụ 1: Giả sử như bạn muốn máy tính xác định một tin nhắn có phải là SPAM hay không
Tác vụ T: Xác định 1 tin nhắn có phải SPAM hay không?

Kinh nghiệm E: Xem lại những tin nhắn đánh dấu là SPAM xem có những đặc tính gì để có thể xác định nó là SPAM.
Độ đo P: Là phần trăm số tin nhắn SPAM được phân loại đúng.
- Ví dụ 2: Chương trình nhận dạng số (số từ 0 -> 9)
T: Là nhận dạng được ảnh chứa ký tự số.
E: Đặc trưng để phân loại ký tự số từ tập dữ liệu số cho trước.
P: Độ chính xác của quá trình nhận dạng.
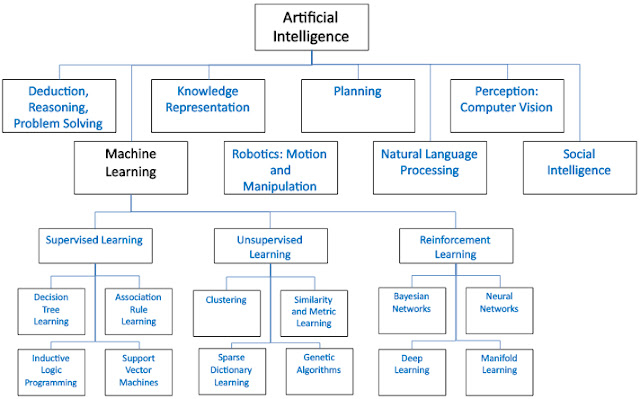

Mối liên hệ giữa Trí Tuệ Nhân Tạo với các nhánh học như Máy Học, Biểu Diễn Tri Thức và Suy Luận,
Xử Lý Ngôn Ngữ Tự Nhiên, Thị Giác Máy Tính…
Sự phát triển mạnh mẽ của Machine Learning
Nhờ vào công nghệ điện toán, ngày nay Machine Learning không còn là máy tính “học” những chuyện trong quá khứ nữa. Machine Learning được sinh ra từ khả năng nhận diện pattern và từ lý thuyết các máy tính có thể “học” mà không cần phải lập trình để thực hiện các tasks cụ thể đó. Về phía các nhà nghiên cứu quan tâm đến trí tuệ nhân tạo, họ lại muốn xem thử liệu máy tính có thể học dữ liệu như thế nào. Yếu tố lặp trong Machine Learning rất quan trọng vì khi các models tiếp xúc với dữ liệu mới, Machine Learning có thể thích ứng được 1 cách độc lập. Machine Learning sẽ “học” các computations trước để trả về các kết quả, các quyết định đáng tin cậy, lặp lại được.
Từ lâu đã có nhiều thuật toán Machine Learning nổi tiếng nhưng khả năng tự động áp dụng các phép tính phức tạp vào Big Data – lặp đi lặp lại với tốc độ nhanh hơn – chỉ mới phát triển gần đây.
Các ứng dụng của Machine Learning đã trở nên quá quen thuộc như:
- Xe tự lái, giảm thiểu tai nạn của Google? Chính là bản chất của machine learning
- Các ưu đãi recommendation online như của Amazong & Netflix? Ứng dụng của Machine Learning trong cuộc sống hằng ngày
- Muốn biết người dùng nói gì về bạn trên Twitter? Machine Learning kết hợp với sự sáng tạo của quy tắc ngôn ngữ
- Nhận diện lừa đảo? Một trong những nhu cầu sử dụng hiển nhiên ngày nay
Tham khảo thêm các vị trí tuyển dụng Machine Learning lương cao cho bạn
Làm thế nào để có những hệ thống machine learrning tốt?
- Khả năng chuẩn bị dữ liệu
- Thuật toán – căn bản & nâng cao
- Quy trình tự động và quy trình lặp lại
- Khả năng scale
- Ensemble modeling
Những đối tượng nào đang xài Machine Learning?
Hầu hết mọi ngành công nghiệp đang làm việc với hàm lượng lớn dữ liệu đều nhận ra tầm quan trọng của công nghệ Machine Learning. Những insights từ nguồn dữ liệu này – chủ yếu dạng realtime – sẽ giúp các tổ chức vận hành hiệu quả hơn hoặc tạo được lợi thế cạnh tranh so với các đối thủ.
- Các dịch vụ tài chính
Ngân hàng và những doanh nghiệp hoạt động trong lĩnh vực tài chính sử dụng công nghệ Machine Learning với 2 mục đích chính: xác định insights trong dữ liệu và ngăn chặn lừa đảo. Insights sẽ biết được các cơ hội đầu tư hoặc thông báo đến nhà đầu tư thời điểm giao dịch hợp lý. Data mining cũng có thể tìm được những khách hàng đang có hồ sơ rủi ro cao hoặc sử dụng giám sát mạng để chỉ rõ những tín hiệu lừa đảo.
- Chính phủ
Các tổ chức chính phủ hoạt động về an ninh cộng đồng hoặc tiện ích xã hội sở hữu rất nhiều nguồn dữ liệu có thể khai thác insights. Ví dụ, khi phân tích dữ liệu cảm biến, chính phủ sẽ tăng mức độ hiệu quả của dịch vụ và tiết kiệm chi phí. Machine Learning còn hỗ trợ phát hiện gian lận và giảm thiểu khả năng trộm cắp danh tính.
- Chăm sóc sức khỏe
Machine Learning là 1 xu hướng phát triển nhanh chóng trong ngành chăm sóc sức khỏe, nhờ vào sự ra đời của các thiết bị và máy cảm ứng đeo được sử dụng dữ liệu để đánh giá tình hình sức khỏe của bệnh nhân trong thời gian thực (real-time). Công nghệ Machine Learning còn giúp các chuyên gia y tế xác định những xu hướng hoặc tín hiệu để cải thiện khả năng điều trị, chẩn đoán bệnh.
- Marketing và sales
Dựa trên hành vi mua hàng trước đây, các trang web sử dụng Machine Learning phân tích lịch sử mua hàng, từ đó giới thiệu những vật dụng mà bạn có thể sẽ quan tâm và yêu thích. Khả năng tiếp nhận dữ liệu, phân tích và sử dụng những dữ liệu đó để cá nhân hóa trải nghiệm mua sắm (hoặc thực hiện chiến dịch Marketing) chính là tương tai của ngành bán lẻ.
- Dầu khí
Tìm kiếm những nguồn nguyên liệu mới. Phân tích các mỏ dầu dưới đất. Dự đoán tình trạng thất bại của bộ cảm biến lọc dầu. Sắp xếp các kênh phân phối để đạt hiệu quả và tiết kiệm chi phí. Có thể nói, số lượng các trường hợp sử dụng Machine Learning trong ngành công nghiệp này cực kì lớn và vẫn ngày càng mở rộng.
- Vận tải
Phân tích dữ liệu để xác định patterns & các xu hướng là trọng tâm trong ngành vận tải vì đây là ngành phụ thuộc vào khả năng tận dụng hiệu quả trên mỗi tuyến đường và dự đoán các vấn đề tiềm tàng để gia tăng lợi nhuận. Các chức năng phân tích dữ liệu và modeling của Machine Learning đóng vai trò quan trọng với các doanh nghiệp vận chuyện, vận tải công cộng và các tổ chức vận chuyển khác.
Một số methods machine learning nổi tiếng
Hai methods của Machine Learning được chấp nhận rộng rãi chính là supervised learning (học có giám sát) và unsupervised learning (học không giám sát) nhưng cũng có những methods khác như semisupervised learning (học bán giám sát), reinforcement learning (học tăng cường)
Dưới đây là khái niệm chung về 2 phương pháp phổ biến nhất:
Supervised Learning (SL) là một kĩ thuật học máy để học tập từ tập dữ liệu được gán nhãn cho trước. Tập dữ liệu cho trước sẽ chứa nhiều bộ dữ liệu. Mỗi bộ dữ liệu có cấu trúc theo cặp {x, y} với x được xem là dữ liệu thô (raw data) và y là nhãn của dữ liệu đó. Nhiệm vụ của SL là dự đoán đầu ra mong muốn dựa vào giá trị đầu vào. Dễ nhận ra, học có GIÁM SÁT tức là máy học dựa vào sự trợ giúp của con người, hay nói cách khác con người dạy cho máy học và giá trị đầu ra mong muốn được định trước bởi con người. Tập dữ liệu huấn luyện hoàn toàn được gán nhãn dựa vào con người. Tập càng nhỏ thì máy tính học càng ít.
SL cũng được áp dụng cho 2 nhóm bài toán chính là bài toán dự đoán (regression problem) và bài toán phân lớp (classification problem).
Kỹ thuật SL thực chất là để xây dựng một hàm có thể xuất ra giá trị đầu ra tương ứng với tập dữ liệu. Ta gọi hàm này là hàm h(x) và mong muốn hàm này xuất ra đúng giá trị y với một hoặc nhiều tập dữ liệu mới khác với dữ liệu được học. Hàm h(x) cần các loại tham số học khác nhau tùy thuộc với nhiều bài toán khác nhau. Việc học từ tập dữ liệu (training) cũng chính là tìm ra bộ tham số học cho hàm h(x).
Unsupervised learning (UL) là một kĩ thuật của máy học nhằm tìm ra một mô hình hay cấu trúc bị ẩn bơi tập dữ liệu KHÔNG được gán nhãn cho trước. UL khác với SL là không thể xác định trước output từ tập dữ liệu huấn luyện được. Tùy thuộc vào tập huấn luyện kết quả output sẽ khác nhau. Trái ngược với SL, tập dữ liệu huấn luyện của UL không do con người gán nhãn, máy tính sẽ phải tự học hoàn toàn. Có thể nói, học KHÔNG GIÁM SÁT thì giá trị đầu ra sẽ phụ thuộc vào thuật toán UL.
Ứng dụng: Ứng dụng phổ biến nhất của học không giám sát là gom cụm (cluster). Đương nhiên sẽ có nhiều ứng dụng khác, có cơ hội tôi sẽ đề cập thêm. Ứng dụng này dễ nhận ra nhất là Google và Facebook. Google có thể gom nhóm các bài báo có nội dung gần nhau, hoặc Facebook có thể gợi ý kết bạn có nhiều bạn chung cho bạn. Các bài báo có cùng nội dung sẽ được gom lại thành một nhóm (cluster) phân biệt với các nhóm khác. Dữ liệu huấn luyện là các bài báo từ quá khứ tới hiện tại và tăng dần theo thời gian. Dễ nhận ra rằng dữ liệu không thể gán nhãn bởi con người. Khi một bài báo mới được cho vào input, nó sẽ tìm cụm (cluster) gần nhất với bài báo đó và gợi ý những bài liên quan.
Tham khảo thêm các vị trí tuyển dụng Machine Learning lương cao cho bạn
Nguồn tổng hợp: SAS & CAPHUUQUAN

